Permutation tests are a class of statistical hypothesis tests that use computational work to create what we call a sampling distribution. You may be familiar with sampling distributions from your introductory statistics course in which case you likely ran into the sampling distribution modeled as a t-distribution (for use in a t-test or a t confidence interval). We will not discuss t-tests in this course, but we will set up the structure of a hypothesis test. Before we see the structure, however, let’s do an example.
14.1 Example: Friend or Foe
This example comes from Investigation 1.1: Friend or Foe? Chance and Rossman (2018). The idea is to use simulation to determine how likely our data would be if nothing interesting was going on.
In a study reported in the November 2007 issue of Nature, researchers investigated whether infants take into account an individual’s actions towards others in evaluating that individual as appealing or aversive, perhaps laying for the foundation for social interaction (Hamlin, Wynn, and Bloom 2007). In other words, do children who aren’t even yet talking still form impressions as to someone’s friendliness based on their actions? In one component of the study, 10-month-old infants were shown a “climber” character (a piece of wood with “googly” eyes glued onto it) that could not make it up a hill in two tries. Then the infants were shown two scenarios for the climber’s next try, one where the climber was pushed to the top of the hill by another character (the “helper” toy) and one where the climber was pushed back down the hill by another character (the “hinderer” toy). The infant was alternately shown these two scenarios several times. Then the child was presented with both pieces of wood (the helper and the hinderer characters) and asked to pick one to play with. Videos demonstrating this component of the study can be found at http://campuspress.yale.edu/infantlab/media/.
One important design consideration to keep in mind is that in order to equalize potential influencing factors such as shape, color, and position, the researchers varied the colors and shapes of the wooden characters and even on which side the toys were presented to the infants. The researchers found that 14 of the 16 infants chose the helper over the hinderer.
Always Ask
What are the observational units?
infants
What is the variable? What type of variable?
choice of helper or hindered: categorical
What is the statistic?
\(\hat{p}\) = proportion of infants who chose helper = 14/16 = 0.875
What is the parameter?
p = proportion of all infants who might choose helper (not measurable!)
Hypotheses
\(H_0\): Null hypothesis. Babies (or rather, the population of babies under consideration) have no inherent preference for the helper or the hinderer shape.
\(H_A\): Alternative hypothesis. Babies (or rather, the population of babies under consideration) are more likely to prefer the helper shape over the hinderer shape.
p-value is the probability of our data or more extreme if nothing interesting is going on.
completely arbitrary cutoff
\(\rightarrow\)
generally accepted conclusion
p-value \(>\) 0.10
\(\rightarrow\)
no evidence against the null model
0.05 \(<\) p-value \(<\) 0.10
\(\rightarrow\)
moderate evidence against the null model
0.01 \(<\) p-value \(<\) 0.05
\(\rightarrow\)
strong evidence against the null model
p-value \(<\) 0.01
\(\rightarrow\)
very strong evidence against the null model
Computation
# to control the randomnessset.seed(47)# first create a data frame with the Infant dataInfants<-read.delim("http://www.rossmanchance.com/iscam3/data/InfantData.txt")# find the observed number of babies who chose the helperhelp_obs<-Infants|>summarize(prop_help =mean(choice=="helper"))|>pull()help_obs
[1] 0.875
# write a function to simulate a set of infants who are # equally likely to choose the helper or the hindererrandom_choice<-function(rep, num_babies){choice=sample(c("helper", "hinderer"), size =num_babies, replace =TRUE, prob =c(0.5, 0.5))return(mean(choice=="helper"))}# repeat the function many timesmap_dbl(1:10, random_choice, num_babies =16)
num_exper<-5000help_random<-map_dbl(1:num_exper, random_choice, num_babies =16)# the p-value!sum(help_random>=help_obs)/num_exper
[1] 0.0022
# visualize null sampling distributionhelp_random|>data.frame()|>ggplot(aes(x =help_random))+geom_histogram()+geom_vline(xintercept =help_obs, color ="red")+labs(x ="proportion of babies who chose the helper", title ="sampling distribution when null hypothesis is true", subtitle ="that is, no inherent preference for helper or hinderer")
Histogram of sample proportions calculated under the setting where babies have no inherent preference for the helper or the hinderer shape. The red line is at the observed proportion from the Hamlin, Wynn, and Bloom (2007) study.
Logic for what we believe
If we look back to the study, we can tell that the researchers varied color, shape, side, etc. to make sure there was nothing systematic about how the infants chose the block (e.g., if they all watch Blue’s Clues they might love the color blue, so we wouldn’t always want the helper shape to be blue).
The excellent design survey rules out outside influence as the reason so many of the infants chose the helper shape.
We ruled out random chance as the mechanism for the larger number of infants who chose the helper shape. (We reject the null hypothesis.)
We conclude that babies are inclined to be helpful. That is, they are more likely to choose the helper than the hindered. [Note: we don’t have any evidence for why they choose the helper. That is, they might be predisposed. They might be modeling their parents. They might notice that they need a lot of help, etc.]
14.2 Structure of Hypothesis testing
14.2.1 Hypotheses
Hypothesis Testing compares data to the expectation of a specific null hypothesis. If the data are unusual, assuming that the null hypothesis is true, then the null hypothesis is rejected.
The Null Hypothesis, \(H_0\), is a specific statement about a population made for the purposes of argument. A good null hypothesis is a statement that would be interesting to reject.
The Alternative Hypothesis, \(H_A\), is a specific statement about a population that is in the researcher’s interest to demonstrate. Typically, the alternative hypothesis contains all the values of the population that are not included in the null hypothesis.
In a two-sided (or two-tailed) test, the alternative hypothesis includes values on both sides of the value specified by the null hypothesis.
In a one-sided (or one-tailed) test, the alternative hypothesis includes parameter values on only one side of the value specified by the null hypothesis. \(H_0\) is rejected only if the data depart from it in the direction stated by \(H_A\).
14.2.2 Other pieces of the process
A statistic is a numerical measurement we get from the sample, a function of the data. [Also sometimes called an estimate.]
A parameter is a numerical measurement of the population. We never know the true value of the parameter.
The test statistic is a quantity calculated from the data that is used to evaluate how compatible the data are with the result expected under the null hypothesis.
The null distribution is the sampling distribution of outcomes for a test statistic under the assumption that the null hypothesis is true.
The p-value is the probability of obtaining the data (or data showing as great or greater difference from the null hypothesis) if the null hypothesis is true. The p-value is a number calculated from the dataset.
Examples of Hypotheses
Identify whether each of the following statements is more appropriate as the null hypothesis or as the alternative hypothesis in a test:
The number of hours preschool children spend watching TV affects how they behave with other children when at day care. Alternative
Most genetic mutations are deleterious. Alternative
A diet of fast foods has no effect on liver function. Null
Cigarette smoking influences risk of suicide. Alternative
Growth rates of forest trees are unaffected by increases in carbon dioxide levels in the atmosphere. Null
The number of hours that grade-school children spend doing homework predicts their future success on standardized tests. Alternative
King cheetahs on average run the same speed as standard spotted cheetahs. Null
The risk of facial clefts is equal for babies born to mothers who take folic acid supplements compared with those from mothers who do not. Null
The mean length of African elephant tusks has changed over the last 100 years. Alternative
Caffeine intake during pregnancy affects mean birth weight. Alternative
14.2.3 All together: structure of a hypothesis test
decide on a research question (which will determine the test)
collect data, specify the variables of interest
state the null (and alternative) hypothesis values (often statements about parameters)
the null claim is the science we want to reject
the alternative claim is the science we want to demonstrate
generate a (null) sampling distribution to describe the variability of the statistic that was calculated along the way
visualize the distribution of the statistics under the null model
get_p_value to measure the consistency of the observed statistic and the possible values of the statistic under the null model
make a conclusion using words that describe the research setting
Example: randomization test on Gerrymandering
Note that the idea of creating a null distribution can apply to a wide range of possible settings. The key is to swap observations around under the null hypothesis where “randomizing under the null hypothesis” helps get the researcher to a conclusion.
Below is a youtube video describing permuting (i.e., randomizing) different voting boundaries to come up with a null distribution of districts. The problem (as stated) is not possible to describe using mathematical functions, but we can derive a solution using computational approaches. [https://www.youtube.com/watch?v=gRCZR_BbjTo]
Example: randomization test on beer and mosquitoes
Great video of how/why computational statistical methods can be extremely useful. And it’s about beer and mosquitoes! John Rauser from Pintrest gives the keynote address at Strata + Hadoop World Conference October 16, 2014. David Smith, Revolution Analytics blog, October 17, 2014. http://blog.revolutionanalytics.com/2014/10/statistics-doesnt-have-to-be-that-hard.html
The big lesson here, IMO, is that so many statistical problems can seem complex, but you can actually get a lot of insight by recognizing that your data is just one possible instance of a random process. If you have a hypothesis for what that process is, you can simulate it, and get an intuitive sense of how surprising your data is. R has excellent tools for simulating data, and a couple of hours spent writing code to simulate data can often give insights that will be valuable for the formal data analysis to come. (David Smith)
Rauser says that the in order to follow a statistical argument that uses simulation, you need three things:
Ability to follow a simple logical argument.
Random number generation.
Iteration
14.3 A note on populations
Throughout most of hypothesis testing we describe inference as the act of making claims about a population based on a sample of data (either a random sample or a randomized experiement). However, there are some times when statistical inference can be helpful when trying to understand an entire population. Consider the following example which seeks to understand a population.
14.3.1 Gender parity in the House of Representatives
Consider political party and self-identified gender as two binary variables (it just so happens that all members of the House of Representatives self-identify as either male or female, including Sarah McBride who is the first transgender member of congress). The situation describes an example where we know the entire population. There is nothing to “test” per se, becasue we know whether or not \(p_D\) is different from \(p_R\) (just look at the numbers!). But there is still an interesting question about the variability of \(p_D\) and \(p_R\) and whether the difference in the proportions could have arisen from a chance mechanism.
Let \(p\) be the proportion of self-identifed women with \(p_D\) and \(p_R\). At the start of the 119th Congress (January 2025), there were 220 Republicans and 215 Democrats. Of the Democrats, 96 identify as women; of the Republicans, 33 identify as women. Note that the numbers calculated are parameters (\(p\)), not statistics (\(\hat{p}\)).
Notice that if gender and party were independent in the House, we would still see fluctuations in the proportions from year to year. So we might ask ourselves, is the difference in proportions (\(p_D - p_R = \frac{96}{215} - \frac{33}{220} = 0.447 - 0.15 = 0.297\)) different from what we would expect the natural variability to be? That is, is the difference in proportions outside the natural range that we would expect given the underlying process by which Congress is chosen, given the null setting?
We suggest that, if the null hypothesis is true, then \(p_D\) and \(p_R\) arose from a common process – whatever that process is, it is the same for both Democrats and Republicans.
A full statistical hypothesis test can be applied to the example above. If we reject the null hypothesis, we are rejecting the claim that the process by which people are elected is independent of gender. That is, we conclude that gender and political party are not independent.
14.4 Hypotheses
\(H_0\): Null hypothesis. The variables beer/water and number of mosquito bites are independent. They have no relationship, and therefore any observed difference between the number of bites on those who drank beer versus those who drank water is due to chance.
\(H_A\): Alternative hypothesis. The variables beer/water and number of mosquito bites are not independent. Any observed difference between the number of bites on those who drank beer versus those who drank water is not due to chance.
14.4.1 Permutation Tests Algorithm
To evaluate the p-value for a permutation test, estimate the sampling distribution of the test statistic when the null hypothesis is true by resampling in a manner that is consistent with the null hypothesis (the number of resamples is finite but can be large!).
Choose a test statistic
Shuffle the data (force the null hypothesis to be true)
Create a null sampling distribution of the test statistic (under \(H_0\))
Find the observed test statistic on the null sampling distribution and compute the p-value (observed data or more extreme). The p-value can be one or two-sided.
Technical Conditions
Permutation tests fall into a broad class of tests called “non-parametric” tests. The label indicates that there are no distributional conditions required about the data (i.e., no condition that the data come from a normal or binomial distribution). However, a test which is “non-parametric” does not meant that there are no conditions on the data, simply that there are no distributional or parametric conditions on the data. The parameters are at the heart of almost all parametric tests.
For permutation tests, we are not basing the test on population parameters, so we don’t need to make any claims about them (i.e., that they are the mean of a particular distribution).
Permutation The different treatments have the same effect. [Note: exchangeability, same population, etc.] If the null hypothesis is true, the labels assigning groups are interchangeable with respect to the probability distribution.
Note that it is our choice of statistic which makes the test more sensitive to some kinds of difference (e.g., difference in mean) than other kinds (e.g., difference in variance).
Parametric For example, the different populations have the same mean.
IMPORTANT KEY IDEA the point of technical conditions for parametric or permutation tests is to create a sampling distribution that accurately reflects the null sampling distribution for the statistic of interest (the statistic which captures the relevant research question information).
14.5 Permutation tests in practice
How is the test interpreted given the different types of sampling which are possibly used to collect the data?
Random Sample The concept of a p-value usually comes from the idea of taking a sample from a population and comparing it to a sampling distribution (from many many random samples).
Random Experiment In the context of a randomized experiment, the p-value represents the observed data compared to “happening by chance.”
The interpretation is direct: if there is only a very small chance that the observed statistic would take such an extreme value, as a result only of the randomization of cases: we reject the null treatment effect hypothesis. CAUSAL!
Observational Study In the context of observational studies the results are less strong, but it is reasonable to conclude that the effect observed in the sample reflects an effect present in the population.
In a sample, consider the difference (or ratio) and ask “Is this difference so large it would rarely occur by chance in a particular sample constructed under the null setting?”
If the data come from a random sample, then the sample (or results from the sample) are probably consistent with the population [i.e., we can infer the results back to the larger population].
14.5.1 Two sample permutation tests
Statistics Without the Agonizing Pain
John Rauser of Pintrest (now Amazon), speaking at Strata + Hadoop 2014. https://blog.revolutionanalytics.com/2014/10/statistics-doesnt-have-to-be-that-hard.html
Logic of hypothesis tests
Choose a statistic that measures the effect.
Construct the sampling distribution under \(H_0\).
Locate the observed statistic in the null sampling distribution.
p-value is the probability of the observed data or more extreme if the null hypothesis is true
Logic of permutation tests
Choose a test statistic.
Shuffle the data (force the null hypothesis to be true). Using the shuffled statistics, create a null sampling distribution of the test statistic (under \(H_0\)).
Find the observed test statistic on the null sampling distribution.
Compute the p-value (observed data or more extreme). The p-value can be one or two-sided.
Data: 200 randomly selected observations from the High School and Beyond survey, conducted on high school seniors by the National Center for Educational Statistics.
Research Question: in the population, do private school kids have a higher math score on average?
# A tibble: 200 × 11
id gender race ses schtyp prog read write math science socst
<int> <chr> <chr> <fct> <fct> <fct> <int> <int> <int> <int> <int>
1 70 male white low public general 57 52 41 47 57
2 121 female white middle public vocational 68 59 53 63 61
3 86 male white high public general 44 33 54 58 31
4 141 male white high public vocational 63 44 47 53 56
5 172 male white middle public academic 47 52 57 53 61
6 113 male white middle public academic 44 52 51 63 61
# ℹ 194 more rows
# A tibble: 2 × 3
schtyp ave_math med_math
<fct> <dbl> <dbl>
1 public 52.2 52
2 private 54.8 53.5
Visualize the relationship of interest
hsb2|>ggplot(aes(x =schtyp, y =math))+geom_boxplot()
Calculate the observed statistic(s)
For fun, we are calculating both the difference in averages as well as the difference in medians. That is, we have two different observed summary statistics to work with.
Visualize the null sampling distribution (average)
set.seed(47)perm_stats<-map(1:500, perm_data, data =hsb2)|>list_rbind()perm_stats|>ggplot(aes(x =perm_ave_diff))+geom_histogram()+geom_vline(aes(xintercept =obs_ave_diff), color ="red")
Visualize the null sampling distribution (median)
perm_stats|>ggplot(aes(x =perm_med_diff))+geom_histogram()+geom_vline(aes(xintercept =obs_med_diff), color ="red")
From these data, the observed differences seem to be consistent with the distribution of differences in the null sampling distribution.
There is no evidence to reject the null hypothesis.
We cannot claim that in the population the average math scores for private school kids is larger than the average math scores for public school kids (p-value = 0.086).
We cannot claim that in the population the median math scores for private school kids is larger than the median math scores for public school kids (p-value = 0.27).
Two-sided hypothesis test
\(H_0: \mu_{private} = \mu_{public}\) and \(H_A: \mu_{private} \ne \mu_{public}\)
From these data, the observed differences seem to be consistent with the distribution of differences in the null sampling distribution.
There is no evidence to reject the null hypothesis.
We cannot claim that there is a difference in average math scores in the population (p-value = 0.154).
We cannot claim that there is a difference in median math scores int he population (p-value = 0.534).
14.5.2 Stratified two-sample permutation test
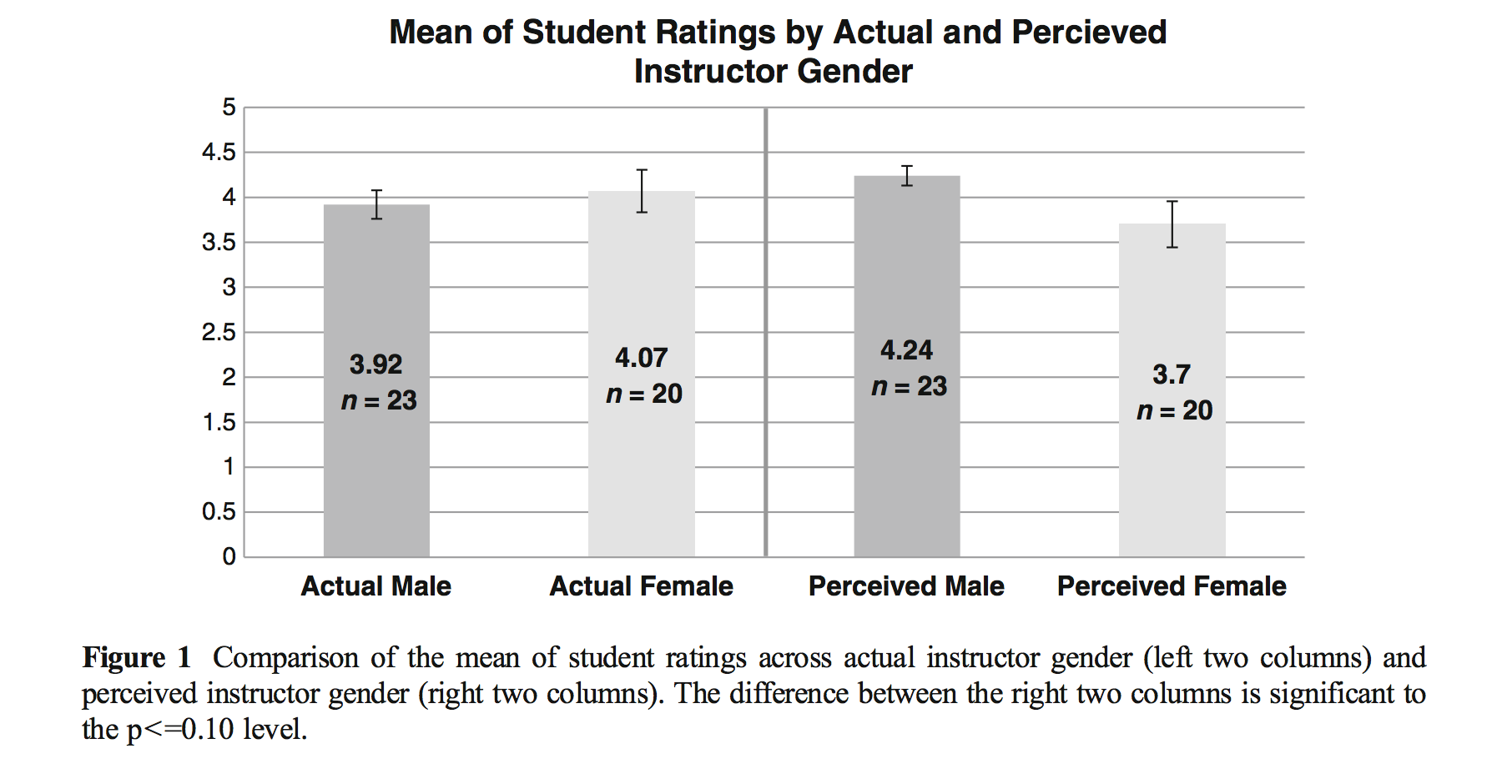
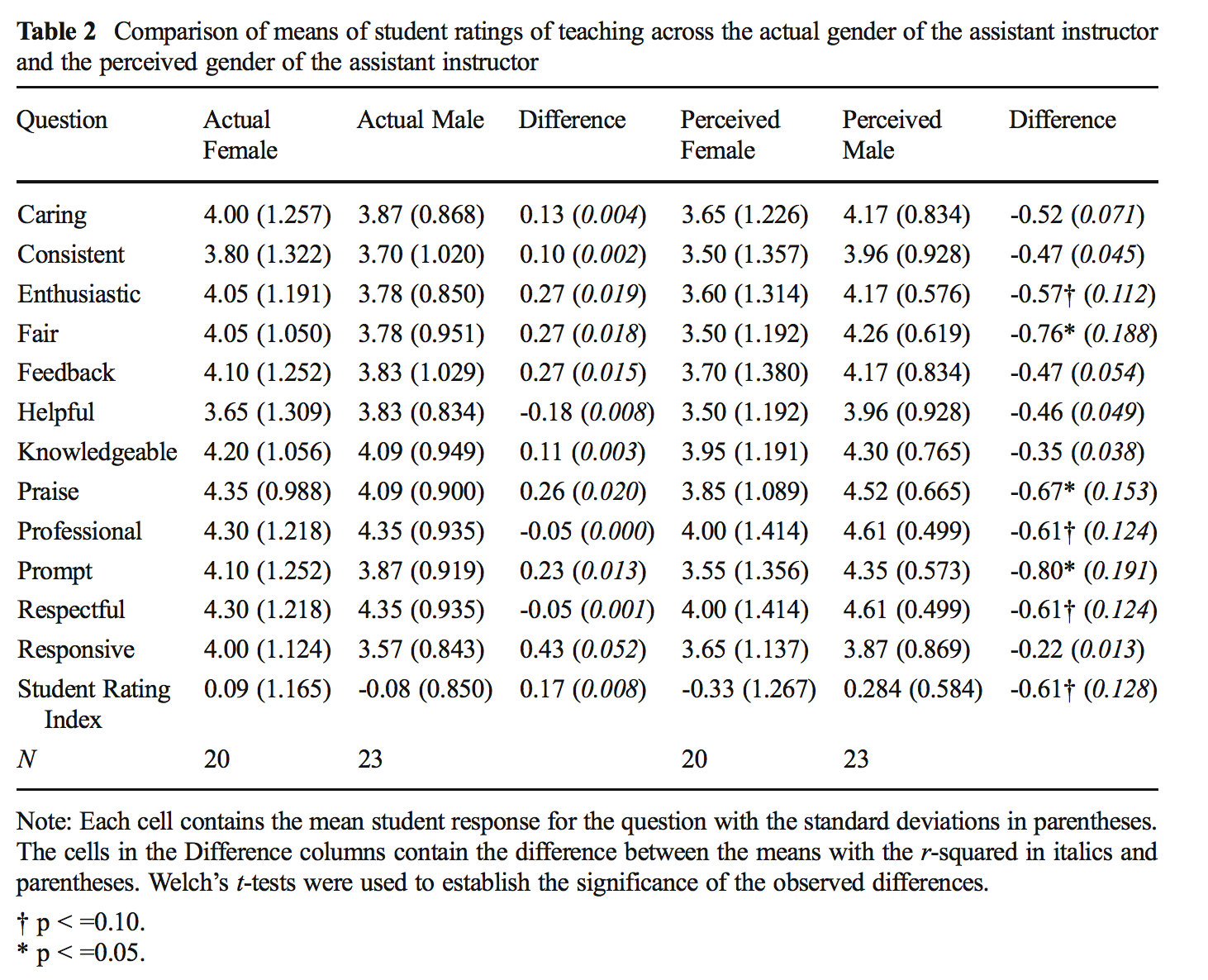
MacNell Teaching Evaluations
Boring et al. (2016) reanalyze data from MacNell et al. (2014). Students were randomized to 4 online sections of a course. In two sections, the instructors swapped identities. Was the instructor who identified as female rated lower on average? (https://www.math.upenn.edu/~pemantle/active-papers/Evals/stark2016.pdf)
# The data come from `permuter` which is no longer kept up as a packagemacnell<-readr::read_csv("https://raw.githubusercontent.com/statlab/permuter/master/data-raw/macnell.csv")#library(permuter)#data(macnell)
library(ggridges)macnell|>mutate(TAID =ifelse(taidgender==1, "male", "female"))|>mutate(TAGend =ifelse(tagender==1, "male", "female"))|>ggplot(aes(y=TAGend, x=overall, group =interaction(TAGend, TAID), fill=TAID))+geom_point(position=position_jitterdodge(jitter.height=0.3, jitter.width =0, dodge.width =0.4), aes(color =TAID))+stat_summary(fun="mean", geom="crossbar", size=.3, width =1,aes(color =TAID), position=position_dodge(width=0.4))+stat_summary(fun="mean", geom="point", shape ="X", size=5, aes(color =TAID), position=position_dodge(width=0.4))+coord_flip()+labs(title ="Overall teaching effectiveness score", x ="", y ="TA gender", color ="TA identifier", fill ="TA identifier")
14.5.2.1 Analysis goal
Want to know if the score for the perceived gender is different.
\[H_0: \mu_{ID.Female} = \mu_{ID.Male}\] > Although for the permutation test, under the null hypothesis not only are the means of the population distributions the same, but the variance and all other aspects of the distributions across perceived gender.
Conceptually, there are two levels of randomization:
\(N_m\) students are randomly assigned to the male instructor and \(N_f\) are assigned to the female instructor.
Of the \(N_j\) assigned to instructor \(j\), \(N_{jm}\) are told that the instructor is male, and \(N_{jf}\) are told that the instructor is female for \(j=m,f\).
The example in class used a modification of the ANOVA F-statistic to compare the observed data with the permuted data test statistics. Depending on the data and question, the permuted test statistic can take on any of a variety of forms.
Data
Hypothesis Question
Statistic
2 categorical
diff in prop
\(\hat{p}_1 - \hat{p}_2\) or \(\chi^2\)
variables
ratio of prop
\(\hat{p}_1 / \hat{p}_2\)
1 numeric
diff in means
\(\overline{X}_1 - \overline{X}_2\)
1 binary
ratio of means
\(\overline{X}_1 / \overline{X}_2\)
diff in medians
\(\mbox{median}_1 - \mbox{median}_2\)
ratio of medians
\(\mbox{median}_1 / \mbox{median}_2\)
diff in SD
\(s_1 - s_2\)
diff in var
\(s^2_1 - s^2_2\)
ratio of SD or VAR
\(s_1 / s_2\)
1 numeric
diff in means
\(\sum n_i (\overline{X}_i - \overline{X})^2\) or
k groups
F stat
paired or
(permute within row)
\(\overline{X}_1 - \overline{X}_2\)
repeated measures
regression
correlation
least sq slope
time series
no serial corr
lag 1 autocross
Depending on the data, hypotheses, and original data collection structure (e.g., random sampling vs random allocation), the choice of statistic for the permutation test will vary.
14.6 Reflection questions
What is a test statistic?
What is a p-value?
Why, for a two sample comparison (treatment A vs treatment B), is it okay to use \(\overline{X}_A - \overline{X}_B\) for a test statistic in a permutation test, but for a t-test the test statistic is necessarily \(t = \frac{\overline{X}_A - \overline{X}_B}{\sqrt{s_A^2/n_A + s_B^2/n_B}}\) (that is, divided by a measure of variability)?
How do you know what to permute in order to create a null sampling distribution?
What is power? What are type I and type II errors?
14.7 Ethics considerations
In a permutation test, sometimes there are many test statistics to choose from (which address the same hypotheses). Why wouldn’t you want to try them all and choose the one that gives you the highest level of discernability (significance)?
When is it acceptable to claim that the resulting “discernable” (i.e., “significant”) outcome is actually a causal relationship (and not just an association)?
Chance, Beth, and Allan Rossman. 2018. Investigating Statistics, Concepts, Applications, and Methods. 3rd ed. http://www.rossmanchance.com/iscam3/.
Hamlin, J. Kiley, Karen Wynn, and Paul Bloom. 2007. “Social Evaluation by Preverbal Infants.”Nature 450: 557–59.
Kraj, Tori. 2017. “Research Suggests Students Are Biased Against Female Lecturers.”The Economist.
MacNell, Lillian, Adam Driscoll, and Andrea Hunt. 2015. “What’s in a Name: Exposing Gender Bias in Student Ratings of Teaching.”Innovative Higher Education 40: 291–303.
Mengel, Friederike, Jan Sauermann, and Ulf Zölitz. 2019. “Gender Bias in Teaching Evaluations.”Journal of the European Economic Association 17: 535–66.