3 Web scraping
3.1 Getting Started
Important tool
Our approach to web scraping relies on the Chrome browser and an extension called a Selector Gadget. Download them here:
Data Acquisition
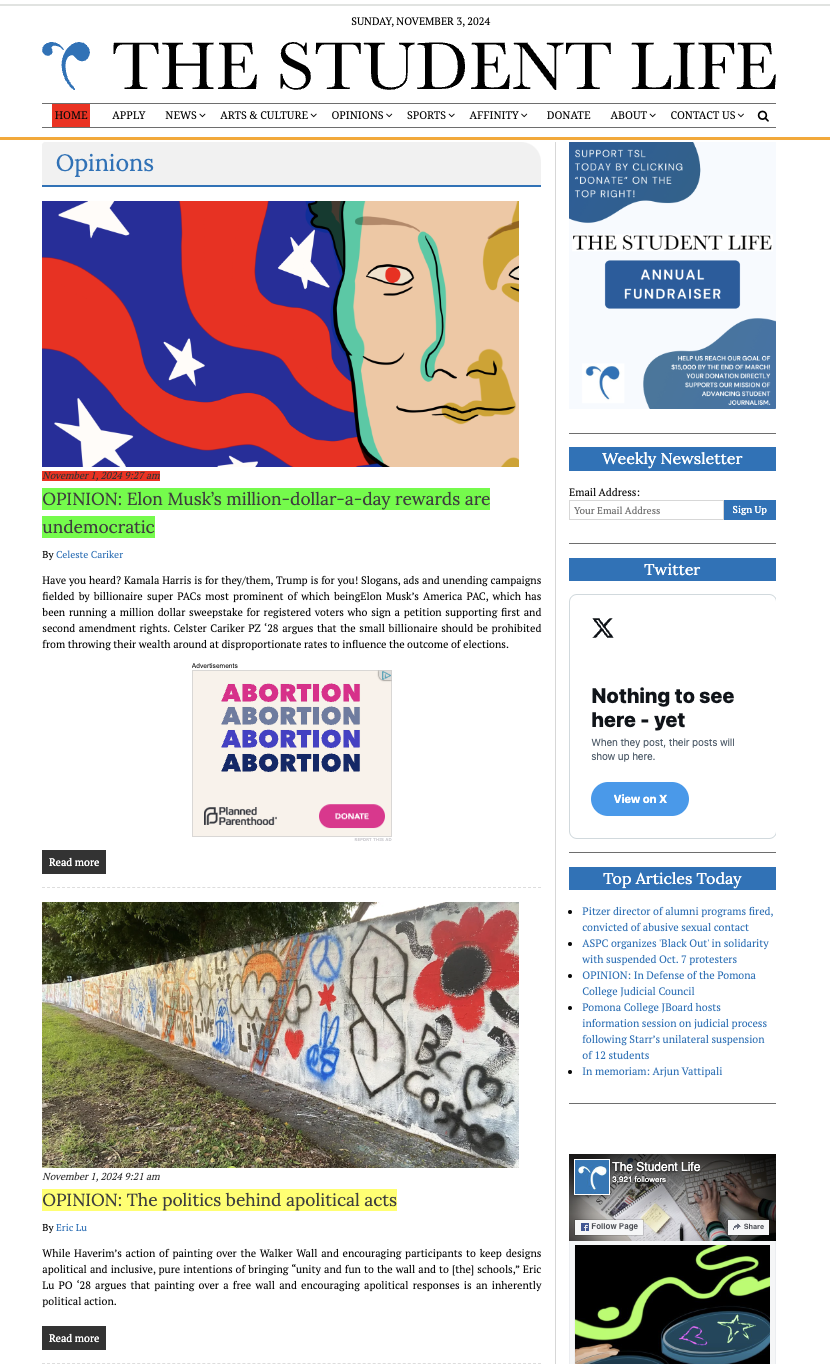
Reading The Student Life
How often do you read The Student Life?
a. Every day
b. 3-5 times a week
c. Once a week
d. Rarely
What do you think is the most common word in the titles of The Student Life opinion pieces?
Analyzing The Student Life
Using the titles of the opinion pieces from The Student Life website, we can figure out the most common words.

How do you think the sentiments in opinion pieces in The Student Life compare across authors?
Roughly the same?
Wildly different?
Somewhere in between?
Using the first paragraph of each opinion article, we can see which others have the most positive and negative sentiment articles.

All of the analysis is done in R! {.centered}
(mostly) with tools you already know!
Common words in The Student Life titles {.smaller}
Code for the earlier plot:
data(stop_words) # from tidytext
tsl_opinion_titles |>
tidytext::unnest_tokens(word, title) |>
anti_join(stop_words) |>
count(word, sort = TRUE) |>
slice_head(n = 20) |>
mutate(word = fct_reorder(word, n)) |>
ggplot(aes(y = word, x = n, fill = log(n))) +
geom_col(show.legend = FALSE) +
theme_minimal(base_size = 16) +
labs(
x = "Number of mentions",
y = "Word",
title = "The Student Life - Opinion pieces",
subtitle = "Common words in the 500 most recent opinion pieces",
caption = "Source: Data scraped from The Student Life on Nov 4, 2024"
) +
theme(
plot.title.position = "plot",
plot.caption = element_text(color = "gray30")
)Avg sentiment scores of first paragraph {.smaller}
Code for the earlier plot:
afinn_sentiments <- get_sentiments("afinn") # need tidytext and textdata
tsl_opinion_titles |>
tidytext::unnest_tokens(word, first_p) |>
anti_join(stop_words) |>
left_join(afinn_sentiments) |>
group_by(authors, title) |>
summarize(total_sentiment = sum(value, na.rm = TRUE), .groups = "drop") |>
group_by(authors) |>
summarize(
n_articles = n(),
avg_sentiment = mean(total_sentiment, na.rm = TRUE),
) |>
filter(n_articles > 1 & !is.na(authors)) |>
arrange(desc(avg_sentiment)) |>
slice(c(1:10, 69:78)) |>
mutate(
authors = fct_reorder(authors, avg_sentiment),
neg_pos = if_else(avg_sentiment < 0, "neg", "pos"),
label_position = if_else(neg_pos == "neg", 0.25, -0.25)
) |>
ggplot(aes(y = authors, x = avg_sentiment)) +
geom_col(aes(fill = neg_pos), show.legend = FALSE) +
geom_text(
aes(x = label_position, label = authors, color = neg_pos),
hjust = c(rep(1,10), rep(0, 10)),
show.legend = FALSE,
fontface = "bold"
) +
geom_text(
aes(label = round(avg_sentiment, 1)),
hjust = c(rep(1.25,10), rep(-0.25, 10)),
color = "white",
fontface = "bold"
) +
scale_fill_manual(values = c("neg" = "#4d4009", "pos" = "#FF4B91")) +
scale_color_manual(values = c("neg" = "#4d4009", "pos" = "#FF4B91")) +
scale_x_continuous(breaks = -5:5, minor_breaks = NULL) +
scale_y_discrete(breaks = NULL) +
coord_cartesian(xlim = c(-5, 5)) +
labs(
x = "negative ← Average sentiment score (AFINN) → positive",
y = NULL,
title = "The Student Life - Opinion pieces\nAverage sentiment scores of first paragraph by author",
subtitle = "Top 10 average positive and negative scores",
caption = "Source: Data scraped from The Student Life on Nov 4, 2024"
) +
theme_void(base_size = 16) +
theme(
plot.title = element_text(hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5, margin = unit(c(0.5, 0, 1, 0), "lines")),
axis.text.y = element_blank(),
plot.caption = element_text(color = "gray30")
)3.2 Where is the data coming from?

tsl_opinion_titles# A tibble: 500 × 4
title authors date first_p
<chr> <chr> <dttm> <chr>
1 Elon Musk’s million-dollar-a-day rewards … Celest… 2024-11-01 16:27:00 have y…
2 The politics behind apolitical acts Eric Lu 2024-11-01 16:21:00 while …
3 In Defense of the Pomona College Judicial… Henri … 2024-11-01 16:15:00 former…
4 ‘Yakking’ isn’t a canon event, party resp… Kabir … 2024-11-01 16:10:00 whirri…
5 The ‘if he wanted to, he would’ mentality… Tess M… 2024-11-01 16:01:00 ladies…
6 You can’t silence us: A united front agai… Outbac… 2024-10-25 11:23:00 in the…
# ℹ 494 more rows3.3 Web scraping
3.3.1 Scraping the web: what? why?
Increasing amount of data is available on the web
HTML data are provided in an unstructured format: you can always copy & paste, but it’s time-consuming and prone to errors
Web scraping is the process of extracting information automatically and transform it into a structured dataset
-
Two different scenarios:
Screen scraping: extract data from source code of website, with html parser (easy) or regular expression matching (less easy).
Web APIs (application programming interface): website offers a set of structured http requests that return JSON or XML files.
3.3.2 Hypertext Markup Language
Most of the data on the web is largely available as HTML - while it is structured (hierarchical) it often is not available in a form useful for analysis (flat / tidy).
<html>
<head>
<title>This is a title</title>
</head>
<body>
<p align="center">Hello world!</p>
<br/>
<div class="name" id="first">John</div>
<div class="name" id="last">Doe</div>
<div class="contact">
<div class="home">555-555-1234</div>
<div class="home">555-555-2345</div>
<div class="work">555-555-9999</div>
<div class="fax">555-555-8888</div>
</div>
</body>
</html>Some HTML elements
-
<html>: start of the HTML page -
<head>: header information (metadata about the page) -
<body>: everything that is on the page -
<p>: paragraphs -
<b>: bold -
<table>: table -
<div>: a container to group content together -
<a>: the “anchor” element that creates a hyperlink
3.3.3 rvest
- The rvest package makes basic processing and manipulation of HTML data straight forward
- It is designed to work with pipelines built with
|> - rvest.tidyverse.org

Core functions:
read_html()- read HTML data from a url or character string.html_elements()- select specified elements/tags from the HTML document using CSS selectors.html_element()- select a single element/tag from the HTML document using CSS selectors.html_table()- parse an HTML table into a data frame.html_text()/html_text2()- extract element’s/tag’s text content.html_name- extract an element’s/tag’s name(s).html_attrs- extract all attributes.html_attr- extract attribute value(s) by name.
html, rvest, & xml2 {.smaller}
html <-
'<html>
<head>
<title>This is a title</title>
</head>
<body>
<p align="center">Hello world!</p>
<br/>
<div class="name" id="first">John</div>
<div class="name" id="last">Doe</div>
<div class="contact">
<div class="home">555-555-1234</div>
<div class="home">555-555-2345</div>
<div class="work">555-555-9999</div>
<div class="fax">555-555-8888</div>
</div>
</body>
</html>'read_html(html){html_document}
<html>
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body>\n <p align="center">Hello world!</p>\n <br><div class="name" ...3.3.4 Selecting elements
read_html(html) |> html_elements("p"){xml_nodeset (1)}
[1] <p align="center">Hello world!</p>read_html(html) |> html_elements("p") |> html_text()[1] "Hello world!"read_html(html) |> html_elements("p") |> html_name()[1] "p"read_html(html) |> html_elements("p") |> html_attrs()[[1]]
align
"center" read_html(html) |> html_elements("p") |> html_attr("align")[1] "center"read_html(html) |> html_elements("div"){xml_nodeset (7)}
[1] <div class="name" id="first">John</div>
[2] <div class="name" id="last">Doe</div>
[3] <div class="contact">\n <div class="home">555-555-1234</div>\n ...
[4] <div class="home">555-555-1234</div>
[5] <div class="home">555-555-2345</div>
[6] <div class="work">555-555-9999</div>
[7] <div class="fax">555-555-8888</div>read_html(html) |> html_elements("div") |> html_text()[1] "John"
[2] "Doe"
[3] "\n 555-555-1234\n 555-555-2345\n 555-555-9999\n 555-555-8888\n "
[4] "555-555-1234"
[5] "555-555-2345"
[6] "555-555-9999"
[7] "555-555-8888" 3.3.5 CSS selectors
We will use a tool called SelectorGadget to help us identify the HTML elements of interest by constructing a CSS selector which can be used to subset the HTML document.
Some examples of basic selector syntax is below,
| Selector | Example | Description |
|---|---|---|
| .class | .title |
Select all elements with class=“title” |
| #id | #name |
Select all elements with id=“name” |
| element | p |
Select all <p> elements |
| element element | div p |
Select all <p> elements inside a <div> element |
| element>element | div > p |
Select all <p> elements with <div> as a parent |
| [attribute] | [class] |
Select all elements with a class attribute |
| [attribute=value] | [class=title] |
Select all elements with class=“title” |
CSS classes and ids
classandidare used to style elements (e.g., change their color!)classcan be applied to multiple different elementsidis unique to each element
read_html(html) |> html_elements(".name"){xml_nodeset (2)}
[1] <div class="name" id="first">John</div>
[2] <div class="name" id="last">Doe</div>read_html(html) |> html_elements("div.name"){xml_nodeset (2)}
[1] <div class="name" id="first">John</div>
[2] <div class="name" id="last">Doe</div>read_html(html) |> html_elements("#first"){xml_nodeset (1)}
[1] <div class="name" id="first">John</div>
3.3.6 Text with html_text() vs. html_text2()
html = read_html(
"<p>
First sentence in the paragraph.
Second sentence that follows a literal line break. <br>Third sentence will start on a new line in the rendered html, but doesn't have a line break as part of the code.
</p>"
)html |> html_text()[1] " \n First sentence in the paragraph.\n Second sentence that follows a literal line break. Third sentence will start on a new line in the rendered html, but doesn't have a line break as part of the code.\n "html |> html_text2()[1] "First sentence in the paragraph. Second sentence that follows a literal line break.\nThird sentence will start on a new line in the rendered html, but doesn't have a line break as part of the code."html_text2() collapses any white space (including \n) into a single space, and turns <br> into \n.
3.3.7 HTML tables with html_table()
html_table =
'<html>
<head>
<title>This is a title</title>
</head>
<body>
<table>
<tr> <th>a</th> <th>b</th> <th>c</th> </tr>
<tr> <td>1</td> <td>2</td> <td>3</td> </tr>
<tr> <td>2</td> <td>3</td> <td>4</td> </tr>
<tr> <td>3</td> <td>4</td> <td>5</td> </tr>
</table>
</body>
</html>'read_html(html_table) |>
html_elements("table") |>
html_table()[[1]]
# A tibble: 3 × 3
a b c
<int> <int> <int>
1 1 2 3
2 2 3 4
3 3 4 53.3.8 SelectorGadget
SelectorGadget (selectorgadget.com) is a javascript based tool that helps you interactively build an appropriate CSS selector for the content you are interested in.
3.3.9 Recap
- Use the SelectorGadget identify tags for elements you want to grab
- Use the rvest R package to first read in the entire page (into R) and then parse the object you’ve read in to the elements you’re interested in
- Put the components together in a data frame (a tibble) and analyze it like you analyze any other data
3.4 Plan for webscraping
- Read in the entire page
- Scrape opinion title and save as
title - Scrape author and save as
author - Scrape date and save as
date - Create a new data frame called
tsl_opinionwith variablestitle,author, anddate
3.4.1 Read in the entire page
tsl_page <- read_html("https://tsl.news/category/opinions/")
tsl_page{html_document}
<html lang="en-US">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body class="archive category category-opinions category-2244 custom-back ...- we need to convert into something more familiar, like a data frame
3.4.2 Scrape title and save as title
tsl_page |>
html_elements(".entry-title a") {xml_nodeset (10)}
[1] <a href="https://tsl.news/opinion-opinions-make-journalism-complicated-i ...
[2] <a href="https://tsl.news/opinion-dont-fill-up-your-calendar-do-nothing- ...
[3] <a href="https://tsl.news/opinion-goyard-doesnt-make-you-hot/" title="OP ...
[4] <a href="https://tsl.news/opinion-why-are-we-so-obsessed-with-memorializ ...
[5] <a href="https://tsl.news/opinion-life-is-a-fedora-why-i-wear-fedoras-an ...
[6] <a href="https://tsl.news/opinion-its-time-to-start-enjoying-your-coffee ...
[7] <a href="https://tsl.news/opinion-do-you-love-sneaking-into-malott-i-hav ...
[8] <a href="https://tsl.news/opinion-we-need-a-serious-caring-approach-to-s ...
[9] <a href="https://tsl.news/opinion-the-anonymity-epidemic-rages-on/" titl ...
[10] <a href="https://tsl.news/opinion-before-rebuilding-gaza-the-world-must- ...title <- tsl_page |>
html_elements(".entry-title a") |>
html_text()
title [1] "OPINION: Opinions make journalism complicated. Indifference makes it impossible"
[2] "OPINION: Don’t fill up your calendar, do nothing instead"
[3] "OPINION: Goyard doesn’t make you hot"
[4] "OPINION: Why are we so obsessed with memorializing horrible people?"
[5] "OPINION: Life is a fedora: why I wear fedoras, and why you should too"
[6] "OPINION: It’s time to start enjoying your coffee without a side of homework"
[7] "OPINION: Do you love sneaking into Malott? I have a better alternative"
[8] "OPINION: We need a serious, caring approach to sexual health"
[9] "OPINION: The anonymity epidemic rages on"
[10] "OPINION: Before Rebuilding Gaza, the World Must Confront Who Destroyed It" title <- title |>
str_remove("OPINION: ")
title [1] "Opinions make journalism complicated. Indifference makes it impossible"
[2] "Don’t fill up your calendar, do nothing instead"
[3] "Goyard doesn’t make you hot"
[4] "Why are we so obsessed with memorializing horrible people?"
[5] "Life is a fedora: why I wear fedoras, and why you should too"
[6] "It’s time to start enjoying your coffee without a side of homework"
[7] "Do you love sneaking into Malott? I have a better alternative"
[8] "We need a serious, caring approach to sexual health"
[9] "The anonymity epidemic rages on"
[10] "Before Rebuilding Gaza, the World Must Confront Who Destroyed It"
3.4.4 Scrape date and save as date
date <- tsl_page |>
html_elements(".published") |>
html_text()
date [1] "November 21, 2025 2:03 am" "November 21, 2025 1:05 am"
[3] "November 21, 2025 12:59 am" "November 21, 2025 12:58 am"
[5] "November 13, 2025 11:56 pm" "November 13, 2025 11:53 pm"
[7] "November 13, 2025 11:51 pm" "November 13, 2025 11:04 pm"
[9] "November 13, 2025 10:53 pm" "November 7, 2025 12:44 am" date <- date |>
lubridate::mdy_hm(tz = "America/Los_Angeles")
date [1] "2025-11-21 02:03:00 PST" "2025-11-21 01:05:00 PST"
[3] "2025-11-21 00:59:00 PST" "2025-11-21 00:58:00 PST"
[5] "2025-11-13 23:56:00 PST" "2025-11-13 23:53:00 PST"
[7] "2025-11-13 23:51:00 PST" "2025-11-13 23:04:00 PST"
[9] "2025-11-13 22:53:00 PST" "2025-11-07 00:44:00 PST"3.4.5 Create a new data frame
tsl_opinion <- tibble(
title,
author,
date
)
tsl_opinion# A tibble: 10 × 3
title authors date
<chr> <chr> <dttm>
1 Opinions make journalism complicated. Indifferenc… Parker… 2025-11-21 02:03:00
2 Don’t fill up your calendar, do nothing instead Joelle… 2025-11-21 01:05:00
3 Goyard doesn’t make you hot Ansley… 2025-11-21 00:59:00
4 Why are we so obsessed with memorializing horribl… Alex B… 2025-11-21 00:58:00
5 Life is a fedora: why I wear fedoras, and why you… Nichol… 2025-11-13 23:56:00
6 It’s time to start enjoying your coffee without a… Ansley… 2025-11-13 23:53:00
# ℹ 4 more rows
3.4.6 map() over multiple pages
tsl_opinions <- function(i){
tsl_page <- read_html(paste0("https://tsl.news/category/opinions/page/",i))
title <- tsl_page |>
html_elements(".entry-title a") |>
html_text() |>
str_remove("OPINION: ")
author <- tsl_page |>
html_elements(".author") |>
html_text() |>
tibble() |>
set_names(nm = "authors") |>
filter(str_detect(authors, "By ")) |>
mutate(authors = str_replace(authors, "By ", ""))
date <- tsl_page |>
html_elements(".published") |>
html_text() |>
lubridate::mdy_hm(tz = "America/Los_Angeles")
first_p <- tsl_page |>
html_elements(".entry-content p") |>
html_text() |>
tolower()
tibble(
title,
author,
date,
first_p
)
}
tsl_opinion_titles <- 1:50 |> purrr::map(tsl_opinions) |>
list_rbind()3.5 Web scraping considerations
3.5.1 Check if you are allowed!
library(robotstxt)
paths_allowed("https://tsl.news/category/opinions/")[1] TRUEpaths_allowed("http://www.facebook.com")[1] FALSE3.5.2 Ethics: “Can you?” vs “Should you?”
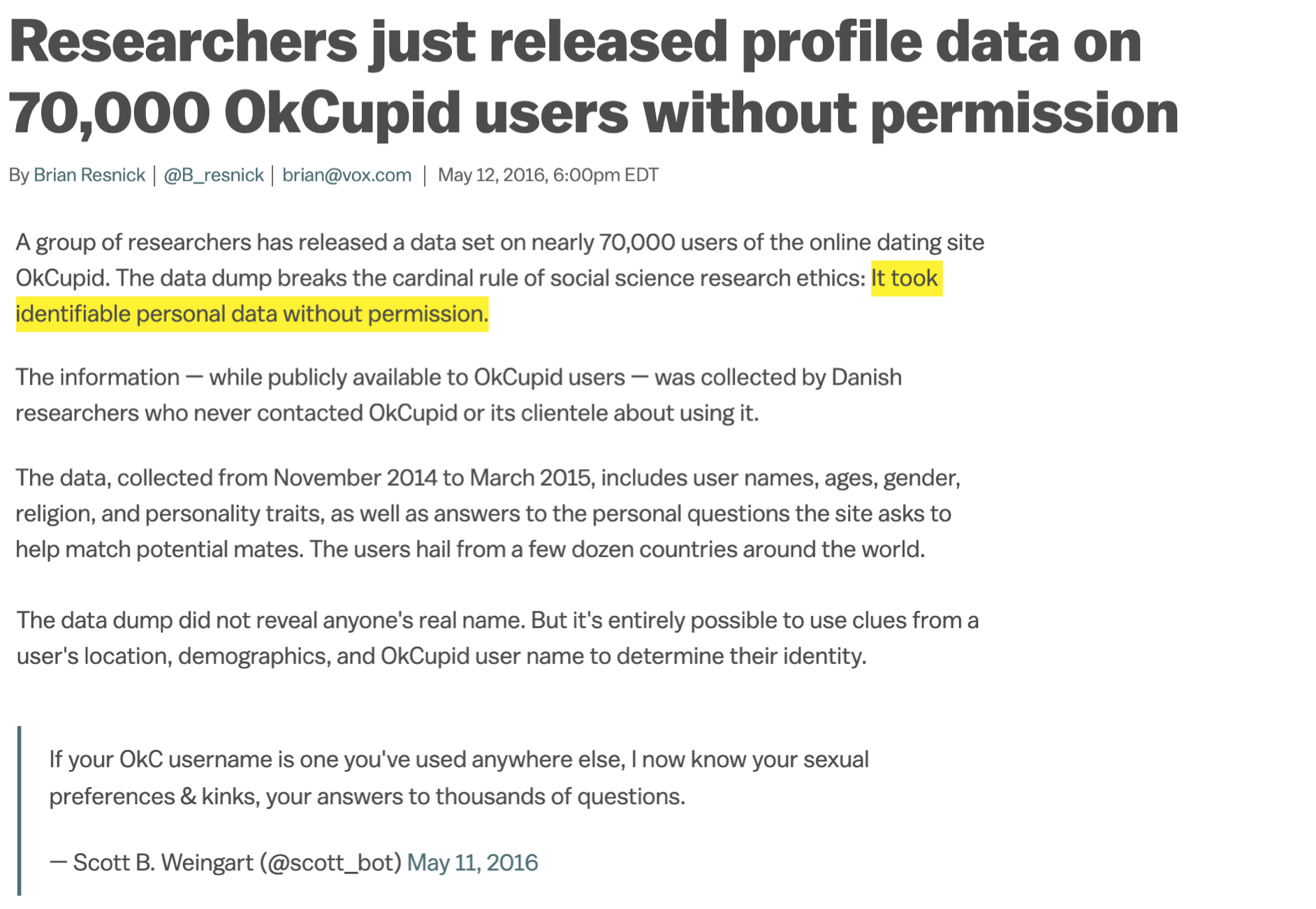
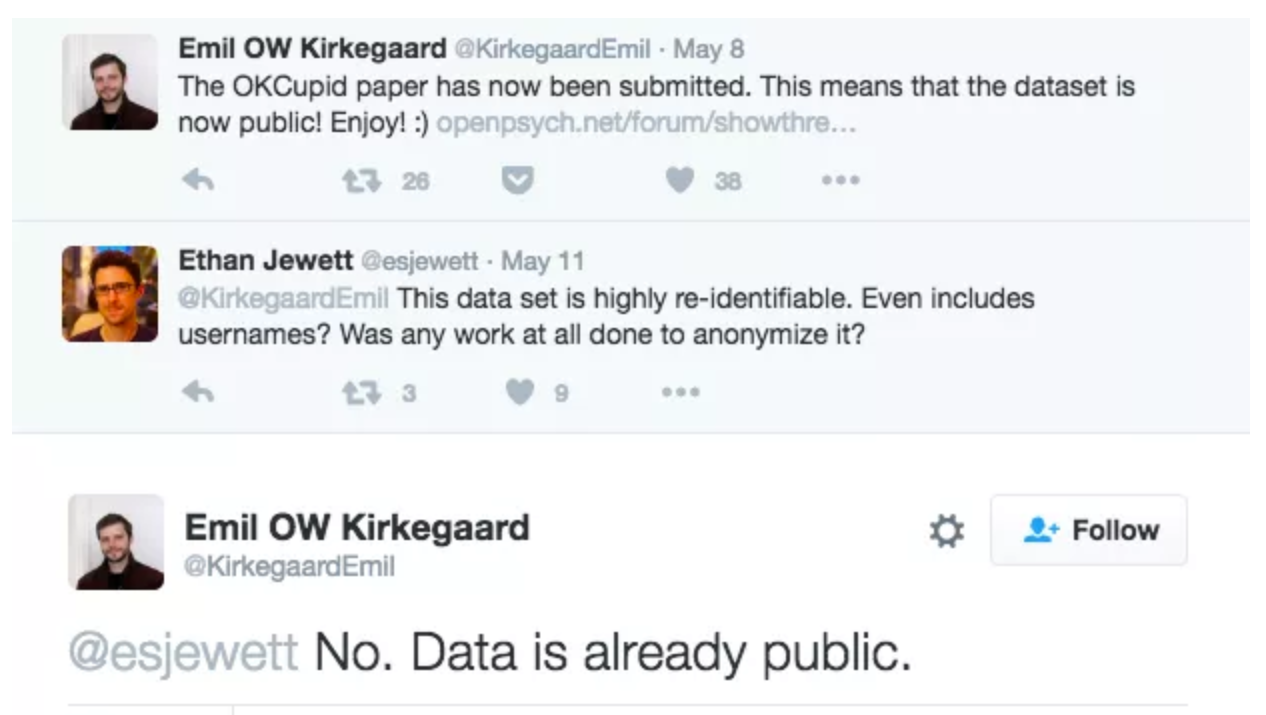
Source: Brian Resnick, Researchers just released profile data on 70,000 OkCupid users without permission, Vox.
3.5.3 Challenges: Unreliable formatting
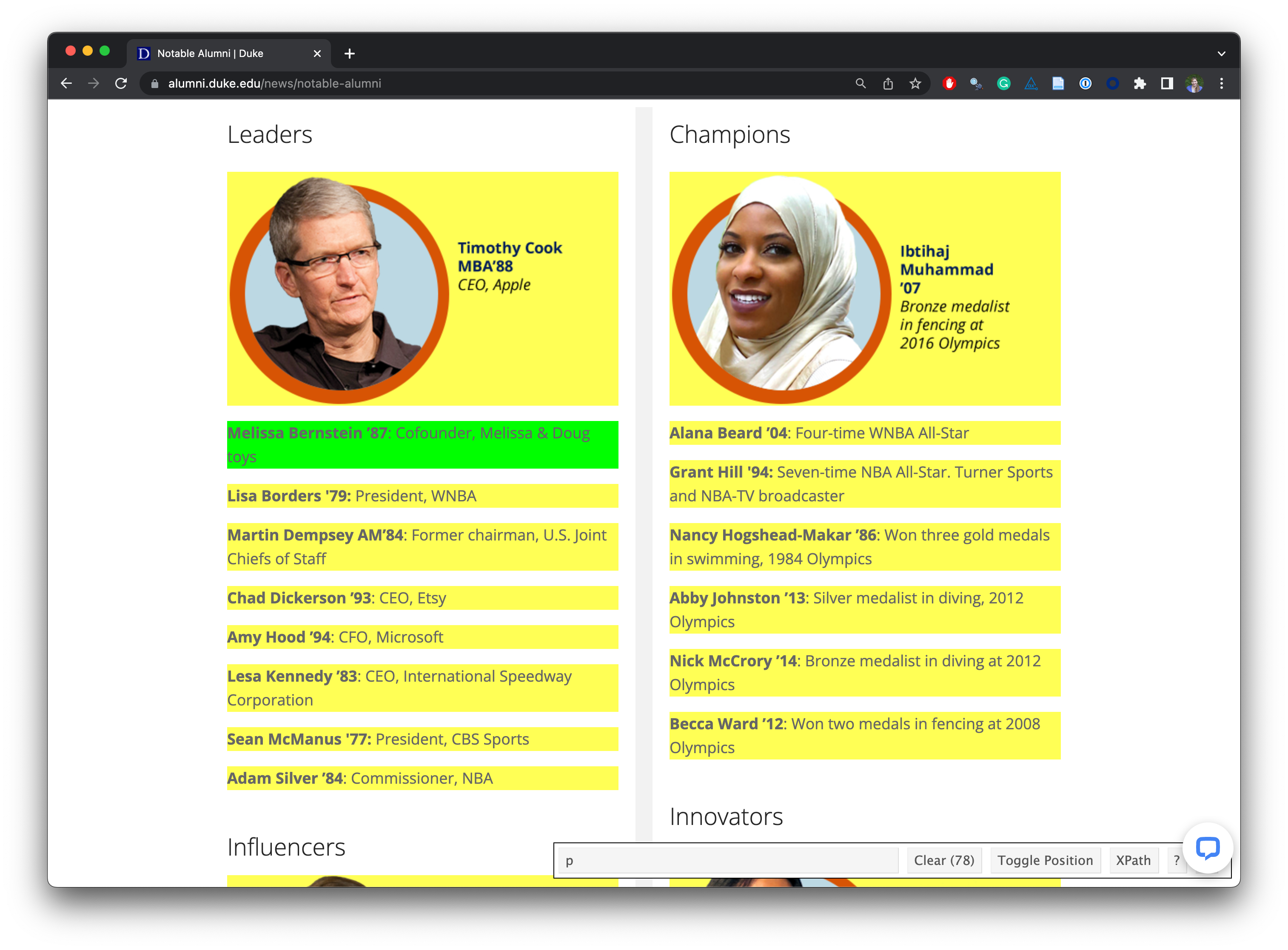
3.5.4 Challenges: Data broken into many pages
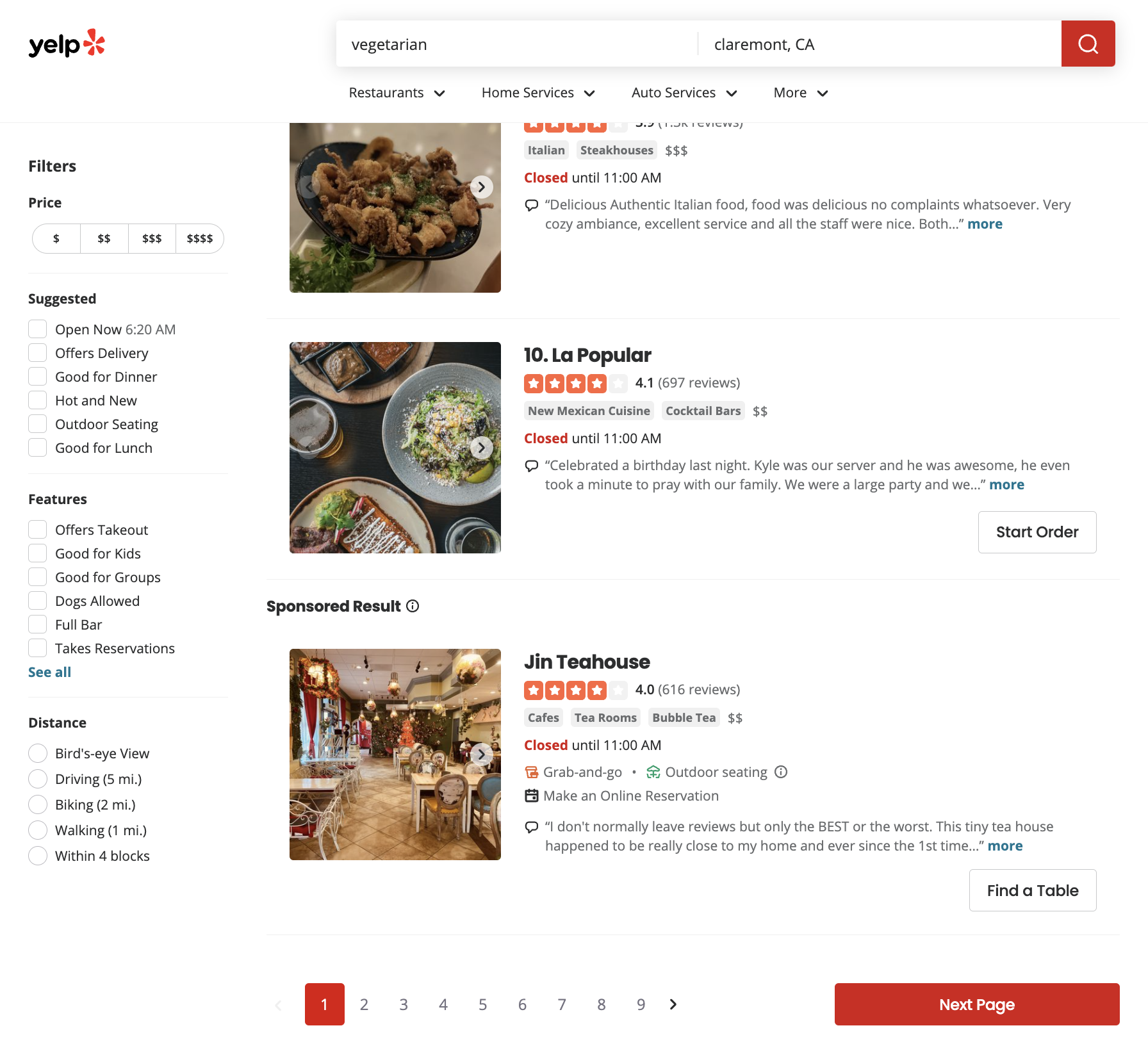
3.6 robots.txt
robots.txt is a file that some websites will publish to clarify what can and cannot be scraped and other constraints about scraping. When a website publishes a robots.txt file, we need to comply with the information in it for moral and legal reasons.
3.7 Reflection questions
- What is the difference between an element and an attribute?
- How does the selector gadget help to scrape information off of an html website?
- What are the special attributes?
- How might you pull out an element by indicating the attributes in that element?
3.8 Ethics considerations
- Why is it that sometimes you can’t / shouldn’t scrape a particular website?
- Are the functions described above always sure-fire? That is, when can they go wrong? What do you need to be aware of?
- If data are “public” (i.e., possible to be scraped), what harm could be done by doing the scraping, compiling the information into one place, and posting the data frame on a website like kaggle?