library(DBI)
library(RMariaDB)
library(dbplyr)
con_air <- DBI::dbConnect(
RMariaDB::MariaDB(),
dbname = "airlines",
host = Sys.getenv("MDSR_HOST"),
user = Sys.getenv("MDSR_USER"),
password = Sys.getenv("MDSR_PWD")
)4 SQL
4.1 What is a Database?
A database is an organized collection of data that is managed by a database management system (DBMS).
A DBMS (e.g., SQL) is the software with which users interact in order to obtain or analyze the data.
Examples of file-based systems
File-based systems are systems that manage and organize data as individual files on storage rather than in a structured database management system (DBMS).
- simple data storage needs
- low volume of data
- static or rarely changing
- single-user applications
Examples of DBMS systems
There are key advantages of DBMS, such as data integrity, concurrent access, complex querying, and indexing.
- information about grocery store purchases
- banking systems
- travel information
- lending books at the library
- academic records
Limitations of file-based systems
- everyone maintains their own dataset
- prone to errors with different formats for different users
- wasted computing space for duplicated sets of information
- definition of data is defined by the programming application
Database Management System (DBMS)
Arose to create systems where the data structure was independent of the analysis.
data stored separated and independently (to the analysis)
a software system that enables users to define, create, maintain, and control access to the database.
allows each user to have their own view (subset) of the database
Advantages of DBMSs
- control of data redundancy
- data consistency
- sharing of data
- improved data integrity
- improved security
- economy of scale
Disadvantages of DBMSs
- complexity
- size
- cost
- higher impact of failure
SQL
SQL is a domain-specific language used to manage data, especially in a relational database management system (RDBMS). It is particularly useful in handling structured data, i.e., data incorporating relations among entities and variables.
Relational: think join
4.2 SQL in R
There are three ways to engage with SQL using R. We will discuss each of them in this chapter, and we will expand on the third method in what follows (using interfaces like DBeaver or Quarto to run actual SQL code directly).
- Using the package dbplyr R will directly translate dplyr code into SQL.
- Using the DBI package, we can send SQL queries through an
rchunk. - Using a
sqlchunk, we can write actual SQL code inside a quarto document.
4.2.1 Translating dplyr code into SQL
Let’s go back to the airlines database to try out some things that we already know how to do in R. Recall that we need the DBI and RMariaDB packages to connect to R; we need the dbplyr package to translate SQL code into R.
The function dbListTables() in the DBI package will tell us what tables exist in the airlines database.
DBI::dbListTables(con_air)[1] "airports" "planes" "carriers" "flights_summary"
[5] "flights" flights <- tbl(con_air, "flights")
carriers <- tbl(con_air, "carriers")Let’s ask a few questions about the data set using data wrangling techniques that should already be familiar.
- Over what years is the
flightsdata taken?
To start, let’s write the commands using tidy dplyr code.
# Source: SQL [?? x 2]
# Database: mysql [mdsr_public@mdsr.crcbo51tmesf.us-east-2.rds.amazonaws.com:3306/airlines]
min_year max_year
<int> <int>
1 2013 2015Because flights is not actually a data.frame in R (but instead a tbl in SQL), the work that was done above was actually performed in SQL. To see the SQL code, we can use the function show_query.
show_query(yrs)<SQL>
SELECT MIN(`year`) AS `min_year`, MAX(`year`) AS `max_year`
FROM `flights`Note the similarity between the R code and the SQL code. We can see SELECT and MIN and MAX which are familiar. The AS function is new, but maybe it that AS does the job of assigning a new name to the output columns. FROM is also new and does the job of piping in a data set to use.
- Create a data set containing only flights between
LAXandBOSin 2012.
la_bos <- flights |>
filter(year == 2012 & ((origin == "LAX" & dest == "BOS") |
(origin == "BOS" & dest == "LAX")))
la_bos# Source: SQL [?? x 21]
# Database: mysql [mdsr_public@mdsr.crcbo51tmesf.us-east-2.rds.amazonaws.com:3306/airlines]
# ℹ 21 variables: year <int>, month <int>, day <int>, dep_time <int>,
# sched_dep_time <int>, dep_delay <int>, arr_time <int>,
# sched_arr_time <int>, arr_delay <int>, carrier <chr>, tailnum <chr>,
# flight <int>, origin <chr>, dest <chr>, air_time <int>, distance <int>,
# cancelled <int>, diverted <int>, hour <int>, minute <int>, time_hour <dttm>show_query(la_bos)<SQL>
SELECT `flights`.*
FROM `flights`
WHERE (`year` = 2012.0 AND ((`origin` = 'LAX' AND `dest` = 'BOS') OR (`origin` = 'BOS' AND `dest` = 'LAX')))The WHERE function in SQL acts as filter() did in R; & has been translated to AND, and | has been translated to OR.
As might be expected, dbplyr doesn’t translate every R command into SQL. After all, SQL is not a statistical software and doesn’t, for example, have a mechanism for creating data visualizations. To track which R commands are connected to SQL see the dbplyr reference sheet.
Because the data set has been subsetted substantially, we could pull it into R to create an R object. Note that now R is aware of the size of the entire data frame (7064 rows and 21 columns). The la_bos object now exists in the R environment and can be explored through the IDE.
la_bos <- la_bos |>
collect()
la_bos# A tibble: 0 × 21
# ℹ 21 variables: year <int>, month <int>, day <int>, dep_time <int>,
# sched_dep_time <int>, dep_delay <int>, arr_time <int>,
# sched_arr_time <int>, arr_delay <int>, carrier <chr>, tailnum <chr>,
# flight <int>, origin <chr>, dest <chr>, air_time <int>, distance <int>,
# cancelled <int>, diverted <int>, hour <int>, minute <int>, time_hour <dttm>?sec-sql-clauses will explore more SQL queries and using SQL keywords. For now, let’s continue learning about the different ways R can talk to SQL.
Always a good idea to terminate the SQL connection when you are done with it.
dbDisconnect(con_air, shutdown = TRUE)4.2.2 SQL queries through the DBI package
Using R as a wrapper, we can send actual SQL code to query data from the connection. It is okay if you aren’t yet able to write SQL commands from scratch, but try to figure out what the command is asking for. As mentioned above, we will start from scratch to learn SQL commands in ?sec-sql-clauses.
Start by setting up the SQL connection in the same way.
con_air <- DBI::dbConnect(
RMariaDB::MariaDB(),
dbname = "airlines",
host = Sys.getenv("MDSR_HOST"),
user = Sys.getenv("MDSR_USER"),
password = Sys.getenv("MDSR_PWD")
)- Look at the first few rows of the
flightsdata.
Because the flights data is not an R object, we can’t open it in R to explore the variables. If we want to see a small bit of the data, we can SELECT everything (i.e, *) from the flights table but LIMIT the query to only the first eight observations.
Note that the code in the dbGetQuery() R function is written in SQL not in R.
A semicolon (;) is typically used to indicate the termination of a SQL statement. They are not always required (particularly when only one statement is being sent), however, it is good practice to use a semicolon at the end of each SQL statement. (Indeed, some SQL dialects require the semicolon at the end of every statement, regardless of whether or not there are more statements following.)
DBI::dbGetQuery(con_air,
"SELECT * FROM flights LIMIT 8;") year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
1 2013 10 1 2 10 -8 453 505
2 2013 10 1 4 2359 5 730 729
3 2013 10 1 11 15 -4 528 530
4 2013 10 1 14 2355 19 544 540
5 2013 10 1 16 17 -1 515 525
6 2013 10 1 22 20 2 552 554
7 2013 10 1 29 35 -6 808 816
8 2013 10 1 29 35 -6 449 458
arr_delay carrier tailnum flight origin dest air_time distance cancelled
1 -12 AA N201AA 2400 LAX DFW 149 1235 0
2 1 FL N344AT 710 SFO ATL 247 2139 0
3 -2 AA N3KMAA 1052 SFO DFW 182 1464 0
4 4 AA N3ENAA 2392 SEA ORD 191 1721 0
5 -10 UA N38473 1614 LAX IAH 157 1379 0
6 -2 UA N458UA 291 SFO IAH 188 1635 0
7 -8 US N551UW 436 LAX CLT 256 2125 0
8 -9 AS N402AS 108 ANC SEA 181 1448 0
diverted hour minute time_hour
1 0 0 10 2013-10-01 00:10:00
2 0 23 59 2013-10-01 23:59:00
3 0 0 15 2013-10-01 00:15:00
4 0 23 55 2013-10-01 23:55:00
5 0 0 17 2013-10-01 00:17:00
6 0 0 20 2013-10-01 00:20:00
7 0 0 35 2013-10-01 00:35:00
8 0 0 35 2013-10-01 00:35:00- How many flights per year are in the
flightstable?
dbGetQuery(con_air,
"SELECT year, count(*) AS num_flights FROM flights GROUP BY year ORDER BY num_flights;") year num_flights
1 2015 5819079
2 2014 5819811
3 2013 6369482Note that we’ve now SELECTed two variables: year and num_flights (which we created along the way using count(*) which is written as n() in R) FROM the flights table. Then we GROUP BY the year variable which retroactively acts on the count(*) function. And last, we ORDER BY (which is similar to arrange()) the new num_flights variable.
Always a good idea to terminate the SQL connection when you are done with it.
dbDisconnect(con_air, shutdown = TRUE)
4.2.3 Direct SQL queries through a sql chunk
Notice that the formatting of the next few chunks is slightly different. Instead of reporting only the inside / code of the chunk, the entire chunk is printed. The SQL chunks are given by {sql} instead of {r} and each SQL chunk is required to connect to a particular database (through the con_air connection).
The same queries have been run.
Start by setting up the SQL connection in the same way.
```{r}
con_air <- DBI::dbConnect(
RMariaDB::MariaDB(),
dbname = "airlines",
host = Sys.getenv("MDSR_HOST"),
user = Sys.getenv("MDSR_USER"),
password = Sys.getenv("MDSR_PWD")
)
``````{sql}
#| connection: con_air
SELECT * FROM flights LIMIT 8;
```| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | tailnum | flight | origin | dest | air_time | distance | cancelled | diverted | hour | minute | time_hour |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2013 | 10 | 1 | 2 | 10 | -8 | 453 | 505 | -12 | AA | N201AA | 2400 | LAX | DFW | 149 | 1235 | 0 | 0 | 0 | 10 | 2013-10-01 00:10:00 |
| 2013 | 10 | 1 | 4 | 2359 | 5 | 730 | 729 | 1 | FL | N344AT | 710 | SFO | ATL | 247 | 2139 | 0 | 0 | 23 | 59 | 2013-10-01 23:59:00 |
| 2013 | 10 | 1 | 11 | 15 | -4 | 528 | 530 | -2 | AA | N3KMAA | 1052 | SFO | DFW | 182 | 1464 | 0 | 0 | 0 | 15 | 2013-10-01 00:15:00 |
| 2013 | 10 | 1 | 14 | 2355 | 19 | 544 | 540 | 4 | AA | N3ENAA | 2392 | SEA | ORD | 191 | 1721 | 0 | 0 | 23 | 55 | 2013-10-01 23:55:00 |
| 2013 | 10 | 1 | 16 | 17 | -1 | 515 | 525 | -10 | UA | N38473 | 1614 | LAX | IAH | 157 | 1379 | 0 | 0 | 0 | 17 | 2013-10-01 00:17:00 |
| 2013 | 10 | 1 | 22 | 20 | 2 | 552 | 554 | -2 | UA | N458UA | 291 | SFO | IAH | 188 | 1635 | 0 | 0 | 0 | 20 | 2013-10-01 00:20:00 |
| 2013 | 10 | 1 | 29 | 35 | -6 | 808 | 816 | -8 | US | N551UW | 436 | LAX | CLT | 256 | 2125 | 0 | 0 | 0 | 35 | 2013-10-01 00:35:00 |
| 2013 | 10 | 1 | 29 | 35 | -6 | 449 | 458 | -9 | AS | N402AS | 108 | ANC | SEA | 181 | 1448 | 0 | 0 | 0 | 35 | 2013-10-01 00:35:00 |
```{sql}
#| connection: con_air
SELECT year, count(*) AS num_flights FROM flights GROUP BY year ORDER BY num_flights;
```| year | num_flights |
|---|---|
| 2015 | 5819079 |
| 2014 | 5819811 |
| 2013 | 6369482 |
Always a good idea to terminate the SQL connection when you are done with it.
dbDisconnect(con_air, shutdown = TRUE)4.3 SQL in DBeaver
DBeaver is a free SQL client that supports MySQL (as well as other dialects like MariaDB, PostgreSQL, and SQLite). While writing SQL code in R has some benefits (e.g., piping results tables into ggplot2 for visualizations), using a SQL client that is designed for SQL queries has benefits as well. In order to use DBeaver, download the client onto your computer and open it from your Applications.
New database connection
Using the pull-down menus, navigate to a new database connection (Database -> New Database Connection). Click on the MySQL icon (and click next). You should see an image similar to Figure 4.1.
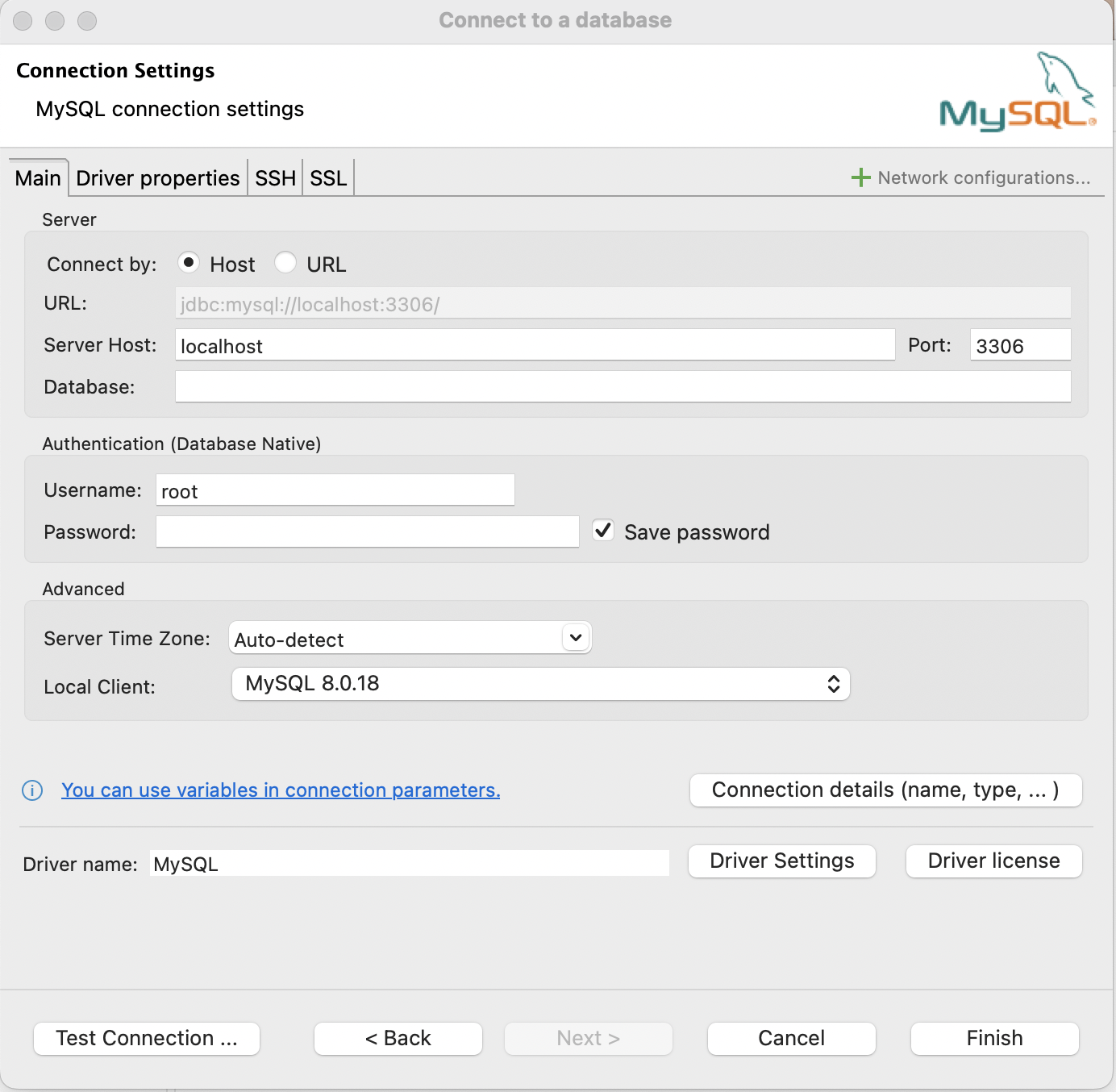
- Keep the
Hostradio button toggled (don’t click onURL) - Where currently it says
Server Host: localhostchangelocalhostto the URL for the MySQL server to which you want to connect. - Change the
Usernameto the appropriate username for the server. - Change the
Passwordto the appropriate password for the server. - Optional: in the
Database:box, include the database you will query. - Click
Finish.
Once the connection is established, you should be able to navigate through the databases and their tables on the left side of the DBeaver window.
Writing SQL statements
Pull up a SQL script by clicking ont he SQL button as seen in Figure 4.2.

Write SQL code. Click on the orange triangle to run the code.
Each lab should be saved as a .sql files that can be turned in. The SQL queries (in the .sql file) should be able to be run by someone else. Use the hashtag (#) to comment out lines so that you can identify particular problems or comment on the query results.
If you did not specify which database to use when you set up the connection, the database can be specified at the top of the .sql file as USE database; (for example, you might want USE airlines;, with the semi-colon, before running your lines of SQL code).
To write text use /* write text here ... */, the slash and asterisk, for any commenting in the .sql file.
4.4 Reflection questions
What are the three main ways to write a SQL query using the Quarto interface?
How is DBeaver similar and/or different from writing queries using R?
Why can’t you use
collect()to pull theflightsdata into your R session?
4.5 Ethics considerations
How / why is
Sys.getenv()used to protect the username and password for the SQL connection?If SQL databases are expensive to maintain, who will then have access to important data? Does it matter?