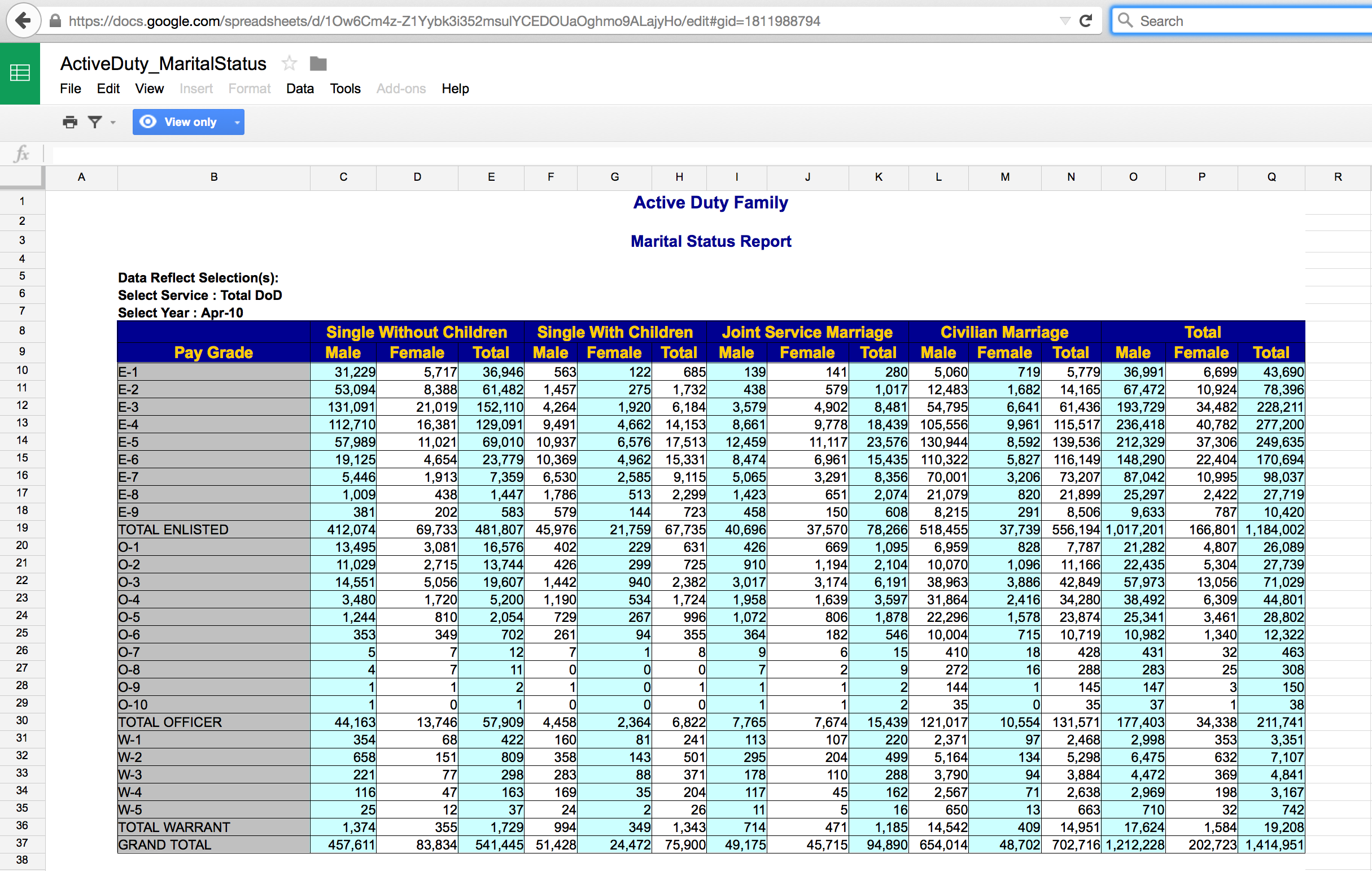
Rows: 38
Columns: 17
$ ...1 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ `Active Duty Family` <chr> NA, "Marital Status Report", NA, "Data Reflect Se…
$ ...3 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 31229, 53094, 131…
$ ...4 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 5717, 8388, 21019…
$ ...5 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 36946, 61482, 152…
$ ...6 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 563, 1457, 4264, …
$ ...7 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 122, 275, 1920, 4…
$ ...8 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 685, 1732, 6184, …
$ ...9 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 139, 438, 3579, 8…
$ ...10 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 141, 579, 4902, 9…
$ ...11 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 280, 1017, 8481, …
$ ...12 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 5060, 12483, 5479…
$ ...13 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 719, 1682, 6641, …
$ ...14 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 5779, 14165, 6143…
$ ...15 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 36991, 67472, 193…
$ ...16 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 6699, 10924, 3448…
$ ...17 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 43690, 78396, 228…
Rows: 30
Columns: 16
$ pay.grade <chr> "E-1", "E-2", "E-3", "E-4", "E-5", "E-6", "E-7", "E-8"…
$ male.sing.wo <dbl> 31229, 53094, 131091, 112710, 57989, 19125, 5446, 1009…
$ female.sing.wo <dbl> 5717, 8388, 21019, 16381, 11021, 4654, 1913, 438, 202,…
$ tot.sing.wo <dbl> 36946, 61482, 152110, 129091, 69010, 23779, 7359, 1447…
$ male.sing.w <dbl> 563, 1457, 4264, 9491, 10937, 10369, 6530, 1786, 579, …
$ female.sing.w <dbl> 122, 275, 1920, 4662, 6576, 4962, 2585, 513, 144, 2175…
$ tot.sing.w <dbl> 685, 1732, 6184, 14153, 17513, 15331, 9115, 2299, 723,…
$ male.joint.NA <dbl> 139, 438, 3579, 8661, 12459, 8474, 5065, 1423, 458, 40…
$ female.joint.NA <dbl> 141, 579, 4902, 9778, 11117, 6961, 3291, 651, 150, 375…
$ tot.joint.NA <dbl> 280, 1017, 8481, 18439, 23576, 15435, 8356, 2074, 608,…
$ male.civ.NA <dbl> 5060, 12483, 54795, 105556, 130944, 110322, 70001, 210…
$ female.civ.NA <dbl> 719, 1682, 6641, 9961, 8592, 5827, 3206, 820, 291, 377…
$ tot.civ.NA <dbl> 5779, 14165, 61436, 115517, 139536, 116149, 73207, 218…
$ male.tot.NA <dbl> 36991, 67472, 193729, 236418, 212329, 148290, 87042, 2…
$ female.tot.NA <dbl> 6699, 10924, 34482, 40782, 37306, 22404, 10995, 2422, …
$ tot.tot.NA <dbl> 43690, 78396, 228211, 277200, 249635, 170694, 98037, 2…