1 Introduction1
1.1 Course Logistics
What is Data Science?
Data science lives at the intersection between statistics, computer science, and discipline knowledge. It is generally the process by which we gain insight from data. Some statistical topics which intersect data science include data wrangling, data visualization, modeling, and statistical inference. Some statistical topics that aren’t usually considered data science include uncovering the convergence rates of particular algorithms. Computer science topics which intersect data science include search algorithms, data storage, and distributed computing. Some computer science topics that aren’t usually considered data science include operating systems, computer networks, computer architecture, and theory of computation. Regardless, it is vitally important to always keep in mind the disciplinary and ethical context in which data science problems are being applied.
What is the content of DS 002R?
This class will cover all aspects of the data science process, from data acquisition to communication. Each of the aspects is important to the data science process, but we will not cover the topics linearly. We will work through acquiring data (e.g., web scraping and using SQL), data exploration (e.g., data wrangling, text analysis), data visualization, data conclusions (e.g., iteration, permutation tests), and data communication (e.g., reproducible workflow).
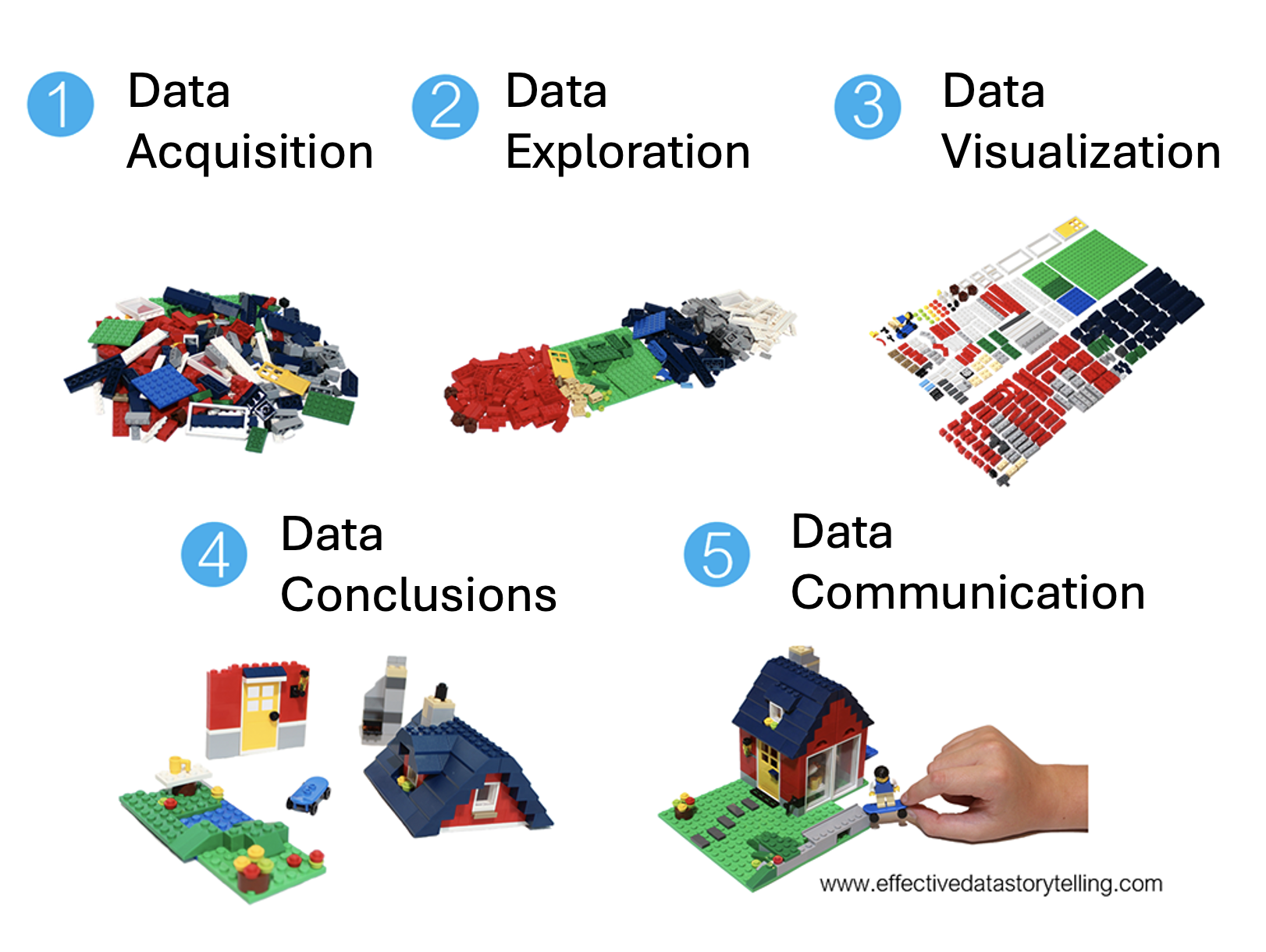
Who should take DS 002R?
Foundations of Data Science will cover many of the concepts and tools for modern data analysis, and therefore the ideas are important for people who would like to do modern data analysis. The tools are particularly important for those who want to approach their own discipline through a quantitative lens.
What are the prerequisites for DS 002R ?
Foundations of Data Science has a formal prerequisite of some computer science. The prerequisite is there because we will move quickly with respect to programming, and students should be familiar with using software and command line programming. The class will use R, but there is no previous knowledge of R required.
Is there overlap with other classes?
The first few weeks of Foundations of Data Science will get students up and running with the software R. The topics in the first few weeks will overlap with other classes, including Computational Statistics and some sections of Introductory Statistics. There are other data science courses at the 5Cs that cover many of the same topics covered in Foundations of Data Science.
When should I take DS 002R?
If you are interested in data science, it is worth your while to take Foundations of Data Science as early as possible in your time at Pomona. It will help you frame the quantitative and computational aspects of the data science projects you will see in your own discipline.
What is the workload for DS 002R?
There is one homework assignment per week, regular quizzes, and 5 mini-projects. Many students report working about 8-10 hours per week on this class.
What software will we use? Will there be any real world applications? Will there be any mathematics? Will there be any CS?
All of the work will be done in R (using RStudio as a front end, called an integrated development environment, IDE). You will need to either download R and RStudio (both are free) onto your own computer or use them on Pomona’s server. All assignments will be posted to private repositories on GitHub. The class is a mix of many real world applications and case studies, some statistics, programming, and communication skills. The projects will allow you to be creative in answering questions of interest to you.
- You may use R on the Pomona server: https://rstudio.pomona.edu/ (All Pomona students will be able to log in immediately. Non-Pomona students need to go to ITS at Pomona to get Pomona login information.)
- If you want to use R on your own machine, you may. Please make sure all components are updated: R is freely available at http://www.r-project.org/ and is already installed on college computers. Additionally, installing R Studio is required https://posit.co/downloads/.
- All assignments should be turned in using Quarto compiled to pdf.
1.2 Background
Data Science includes the full pipeline for working with data. Some of the topics we will cover in DS 002R include:
| DS workflow | in DS002R | beyond DS002R |
|---|---|---|
data acquisition |
web scraping, relational databases |
APIs |
data exploration |
wrangling, strings, regular expressions |
natural language processing |
data visualization |
grammar of graphics |
animations |
data conclusions |
iteration, permutation tests |
predictive modeling, machine learning, AI |
data communication |
yes! |
yes! |
1.2.1 Data
What are data? Oftentimes, the word data brings to mind a spreadsheet, like the one below, which is tidy and describes characteristics of a group of penguins.
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | year |
|---|---|---|---|---|---|---|---|
| Adelie | Torgersen | 39.1 | 18.7 | 181 | 3750 | male | 2007 |
| Adelie | Torgersen | 39.5 | 17.4 | 186 | 3800 | female | 2007 |
| Adelie | Torgersen | 40.3 | 18.0 | 195 | 3250 | female | 2007 |
| Adelie | Torgersen | NA | NA | NA | NA | NA | 2007 |
| Adelie | Torgersen | 36.7 | 19.3 | 193 | 3450 | female | 2007 |
| Adelie | Torgersen | 39.3 | 20.6 | 190 | 3650 | male | 2007 |
- each row = a unit of observation (here, a penguin)
- each column = a measure on some variable of interest, either quantitative (numbers with units) or categorical (discrete possibilities or categories)
- each entry contains a single data value; no analysis, summaries, footnotes, comments, etc, and only one value per cell
But the definition of datum can be much broader:

Each of the following can be thought of as data. How would you wrangle such information into a tidy format?
Data examples:
- the emails in your inbox
- social media texts
- images
- videos
- audio files
For each example, provide:
- the observational units (what does a row represent)
- at least 4 possible variables (what might we record for each observation)
- who might use such data?
1.2.2 Data Science in the Wild
Data science extracts knowledge from within a particular domain of inquiry. Examples from Pomona!
- Shannon Burns (Psychological Science and Neuroscience) uses data to understand brain processes of social communication.
- Anthony (Tony) Clark uses data to improve the safety and reliability of mobile robots.
- Jun Lang (Asian Languages and Literatures) uses data to analyze (1) the intersection of language, gender, and society, and (2) second language acquisition and pedagogy.
- Frank Pericolosi (Physical Education) uses data to improve his team’s chances on the field.
- Ami Radunskaya (Mathematics) uses data to model tumor growth and treatment.
1.3 Tools
We use tools to do the things. But the tools are not the things.
The reproducible data analysis process
- Scriptability \(\rightarrow\) R
- Literate programming \(\rightarrow\) Quarto (via R Studio)
- Version control \(\rightarrow\) Git / GitHub
Scripting and literate programming
Donald Knuth “Literate Programming” (1983)
Let us change our traditional attitude to the construction of programs: Instead of imagining that our main task is to instruct a computer- what to do, let us concentrate rather on explaining to human beings- what we want a computer to do.
- The ideas of literate programming have been around for many years!
- and tools for putting them to practice have also been around
- but they have never been as accessible as the current tools
Reproducibility checklist
- Are the tables and figures reproducible from the code and data?
- Does the code actually do what you think it does?
- In addition to what was done, is it clear why it was done? (e.g., how were parameter settings chosen?)
- Can the code be used for other data?
- Can you extend the code to do other things?
1.3.1 R and R Studio
- You must use both R and R Studio software programs
- R does the programming
- R Studio brings everything together
- You may use Pomona’s server: https://rstudio.pomona.edu/

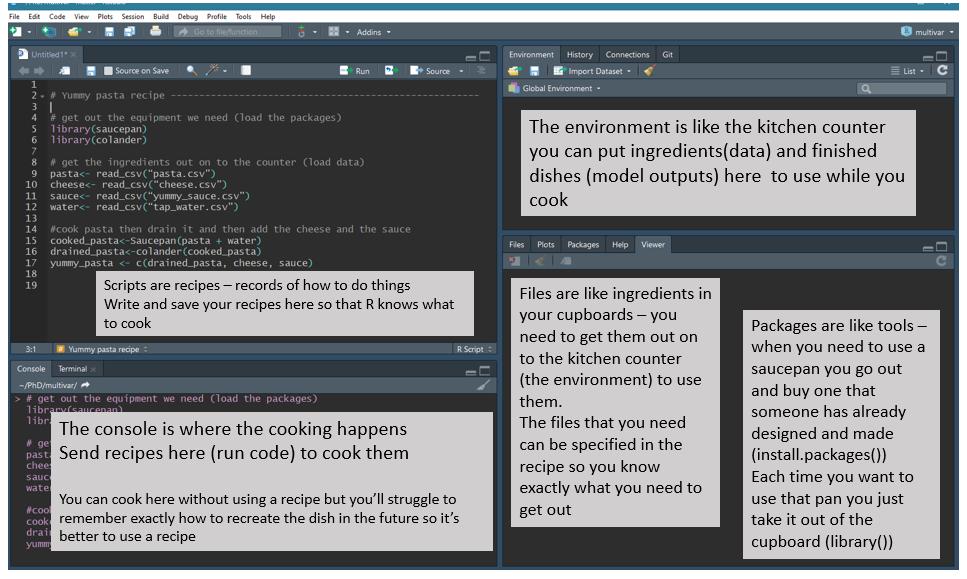
1.3.2 Git & GitHub
- You must submit your assignments via GitHub
- Follow Jenny Bryan’s advice on how to get set-up: http://happygitwithr.com/
- Class specific instructions at https://ds002r-fds.netlify.app/github
Admittedly, there is a steep learning curve with Git. However, it is among the tools which you are most likely to use in your future endeavors, so spending a little time focusing on the concepts now may pay off big time in the future. Beyond practicing and working through http://happygitwithr.com/, you may want to read a little bit about what Git is doing behind the scenes. This reference: Learn git concepts, not commands is very good and accessible.
Tools: a GitHub merge conflict (demo)
- On GitHub (on the web) edit the README document and Commit it with a message describing what you did.
- Then, in RStudio also edit the README document with a different change.
- Commit your changes
- Try to push \(\rightarrow\) you’ll get an error!
- Try pulling
- Resolve the merge conflict and then commit and push
- As you work in teams you will run into merge conflicts, learning how to resolve them properly will be very important.

Steps for weekly homework
- You will get a link to the new assignment (clicking on the link will create a new private repo)
- Use R (within R Studio)
- New Project, version control, Git
- Clone the repo using SSH
- New Project, version control, Git
- If it exists, rename the Rmd file to ds002r-hw#-lname-fname.Rmd
- Do the assignment
-
commitandpushafter every problem
-
- All necessary files must be in the same folder (e.g., data)
1.4 Reproducibility
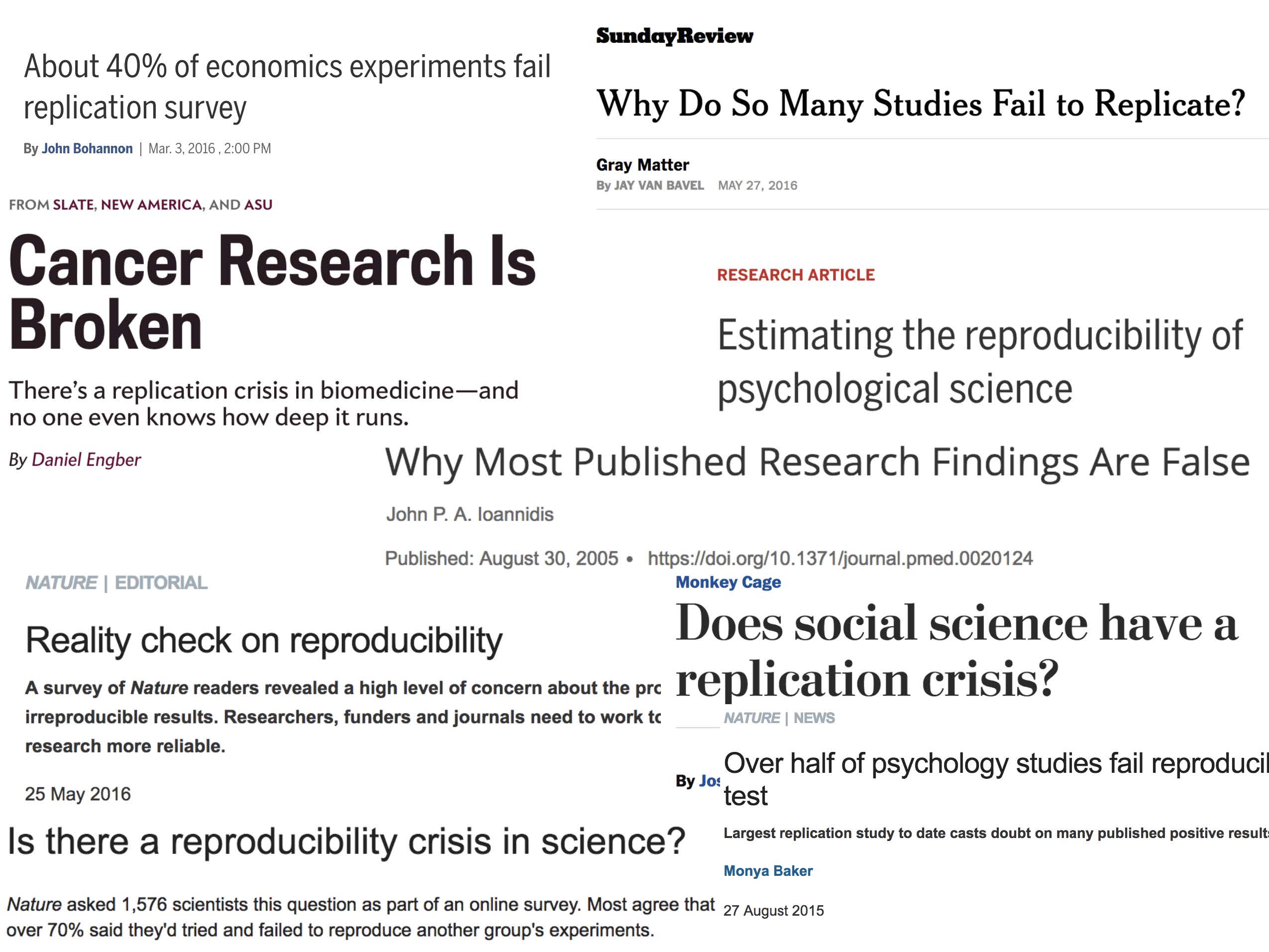
Reproducibility has long been considered an important topic for consideration in any research project. However, recently there has been increased press and available examples for understanding the impact that non-reproducible science can have.
Kitzes, Turek, and Deniz (2018) provide a full textbook on the structure of reproducible research as well as dozens of case studies to help hone skills and consider different aspects of the reproducible pipeline. Below are a handful of examples to get us thinking about reproducibility.
1.4.1 Need for Reproducibility
Example 1
Science retracts gay marriage paper without agreement of lead author LaCour
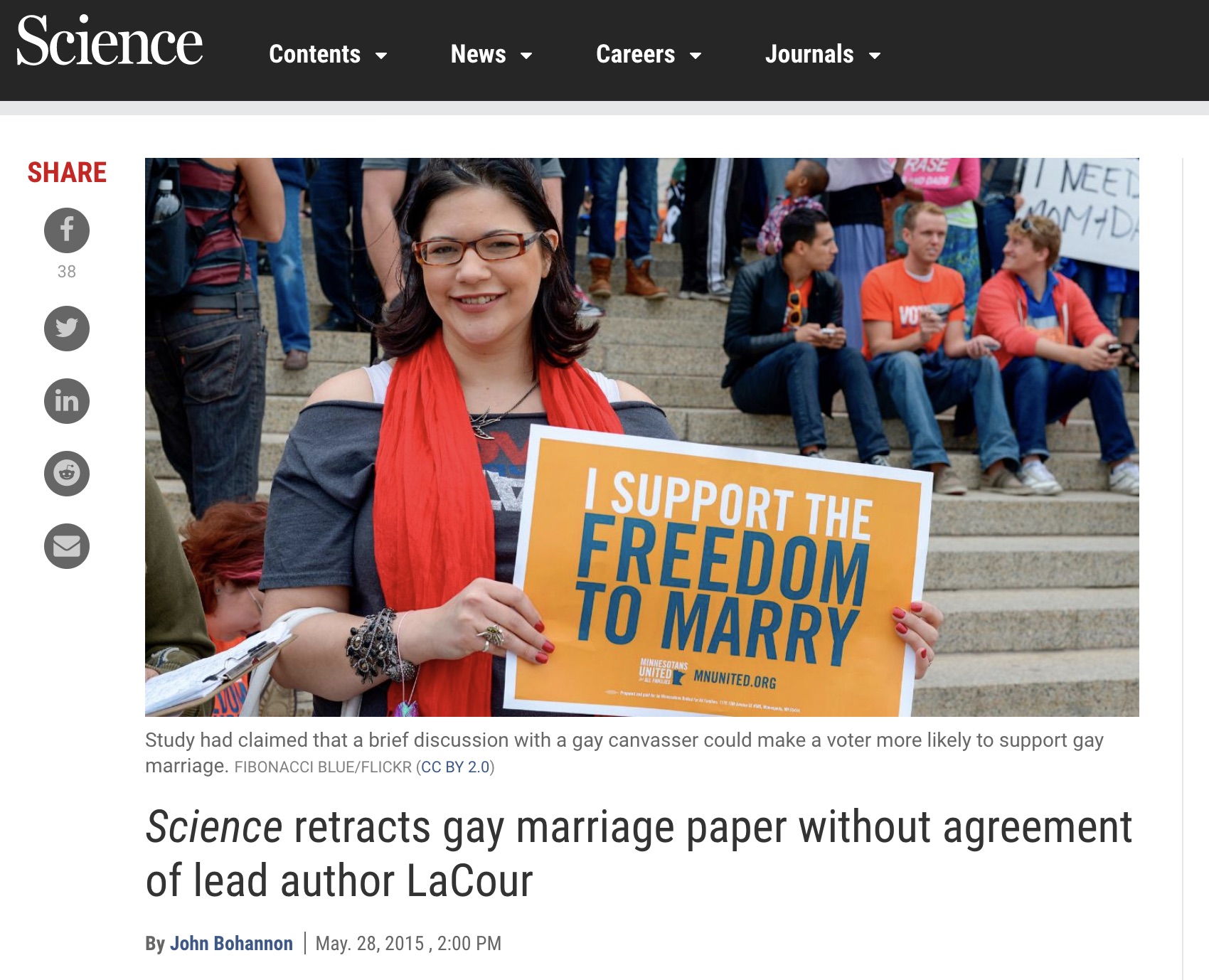
- In May 2015 Science retracted a study of how canvassers can sway people’s opinions about gay marriage published just 5 months prior.
- Science Editor-in-Chief Marcia McNutt:
- Original survey data not made available for independent reproduction of results.
- Survey incentives misrepresented.
- Sponsorship statement false.
- Two Berkeley grad students who attempted to replicate the study quickly discovered that the data must have been faked.
- Methods we’ll discuss can’t prevent this, but they can make it easier to discover issues.
- Source: http://news.sciencemag.org/policy/2015/05/science-retracts-gay-marriage-paper-without-lead-author-s-consent
Example 2
Seizure study retracted after authors realize data got “terribly mixed”

- From the authors of Low Dose Lidocaine for Refractory Seizures in Preterm Neonates:
The article has been retracted at the request of the authors. After carefully re-examining the data presented in the article, they identified that data of two different hospitals got terribly mixed. The published results cannot be reproduced in accordance with scientific and clinical correctness.
- Source: http://retractionwatch.com/2013/02/01/seizure-study-retracted-after-authors-realize-data-got-terribly-mixed/
Example 3
Bad spreadsheet merge kills depression paper, quick fix resurrects it

- The authors informed the journal that the merge of lab results and other survey data used in the paper resulted in an error regarding the identification codes. Results of the analyses were based on the data set in which this error occurred. Further analyses established the results reported in this manuscript and interpretation of the data are not correct.
Original conclusion: Lower levels of CSF IL-6 were associated with current depression and with future depression …
Revised conclusion: Higher levels of CSF IL-6 and IL-8 were associated with current depression …
- Source: http://retractionwatch.com/2014/07/01/bad-spreadsheet-merge-kills-depression-paper-quick-fix-resurrects-it/
Example 4
PNAS paper retracted due to problems with figure and reproducibility (April 2016): http://cardiobrief.org/2016/04/06/pnas-paper-by-prominent-cardiologist-and-dean-retracted/

1.5 Data Examples
What can/can’t Data Science Do?
- Can model the data at hand!
- Can find patterns & visualizations in large datasets.
- Can’t establish causation.
- Can’t represent data if it isn’t there.
Stats / Data Science / Math are not apolitical/agnostic
- “Inner city crime is reaching record levels” (Donald Trump, 8/30/16)
- “The unemployment rate for African-American youth is 59 percent” (Donald Trump 6/20/16)
- “Two million more Latinos are in poverty today than when President Obama took his oath of office less than eight years ago” (Donald Trump 8/25/16)
- “We are now, for the first time ever, energy independent” (Hillary Clinton 8/10/16)
- “If you look worldwide, the number of terrorist incidents have not substantially increased” (Barack Obama 10/13/16)
- “Illegal immigration is lower than it’s been in 40 years” (Barack Obama, 3/17/16)
Source: http://www.politifact.com/truth-o-meter/statements/
1.5.1 College Rankings Systems
Cheating
Bucknell University lied about SAT averages from 2006 to 2012, and Emory University sent in biased SAT scores and class ranks for at least 11 years, starting in 2000. Iona College admitted to fudging SAT scores, graduation rates, retention rates, acceptance rates, and student-to-faculty ratios in order to move from 50th place to 30th for nine years before it was discovered. ( Weapons of Math Destruction, O’Neil, https://weaponsofmathdestructionbook.com/ and http://www.slate.com/articles/business/moneybox/2016/09/how_big_data_made_applying_to_college_tougher_crueler_and_more_expensive.html)
Gaming the system
Point by point, senior staff members tackled different criteria, always with an eye to U.S. News’s methodology. Freeland added faculty, for instance, to reduce class size. “We did play other kinds of games,” he says. “You get credit for the number of classes you have under 20 [students], so we lowered our caps on a lot of our classes to 19 just to make sure.” From 1996 to the 2003 edition (released in 2002), Northeastern rose 20 spots. ( 14 Reasons Why US News College Rankings are Meaningless http://www.liberalartscolleges.com/us-news-college-rankings-meaningless/)
No way to measure “quality of education”
What is “best”? A big part of the ranking system has to do with peer-assessed reputation (feedback loop!).
1.5.2 Trump and Twitter
Analysis of Trump’s tweets with evidence that someone else tweets from his account using an iPhone.
- Aug 9, 2016 http://varianceexplained.org/r/trump-tweets/
My analysis, shown below, concludes that the Android and iPhone tweets are clearly from different people, posting during different times of day and using hashtags, links, and retweets in distinct ways. What’s more, we can see that the Android tweets are angrier and more negative, while the iPhone tweets tend to be benign announcements and pictures.
- Aug 9, 2017 http://varianceexplained.org/r/trump-followup/
There is a year of new data, with over 2700 more tweets. And quite notably, Trump stopped using the Android in March 2017. This is why machine learning approaches like http://didtrumptweetit.com/ are useful, since they can still distinguish Trump’s tweets from his campaign’s by training on the kinds of features I used in my original post.
I’ve found a better dataset: in my original analysis, I was working quickly and used the
I’ve heard some interesting questions that I wanted to follow up on: These come from the comments on the original post and other conversations I’ve had since. Two questions included what device Trump tended to use before the campaign, and what types of tweets tended to lead to high engagement.
1.5.3 Can Twitter Predict Election Results?
In 2013, DiGrazia et al. (2013) published a provocative paper suggesting that polling could now be replaced by analyzing social media data. They analyzed 406 competitive US congressional races using over 3.5 billion tweets. In an article in The Washington Post one of the co-authors, Rojas, writes: “Anyone with programming skills can write a program that will harvest tweets, sort them for content and analyze the results. This can be done with nothing more than a laptop computer.” (Rojas 2013)
What makes using Tweets to predict elections relevant to our class? (See Baumer (2015).)
- The data come from neither an experiment nor a random sample - there must be careful thought applied to the question of to whom the analysis can be generalized. The data were also scraped from the internet.
- The analysis was done combining domain knowledge (about congressional races) with a data source that seems completely irrelevant at the outset (tweets).
- The dataset was quite large! 3.5 billion tweets were collected and a random sample of 500,000 tweets were analyzed.
- The researchers were from sociology and computer science - a truly collaborative endeavor, and one that is often quite efficient at producing high quality analyses.
Activity
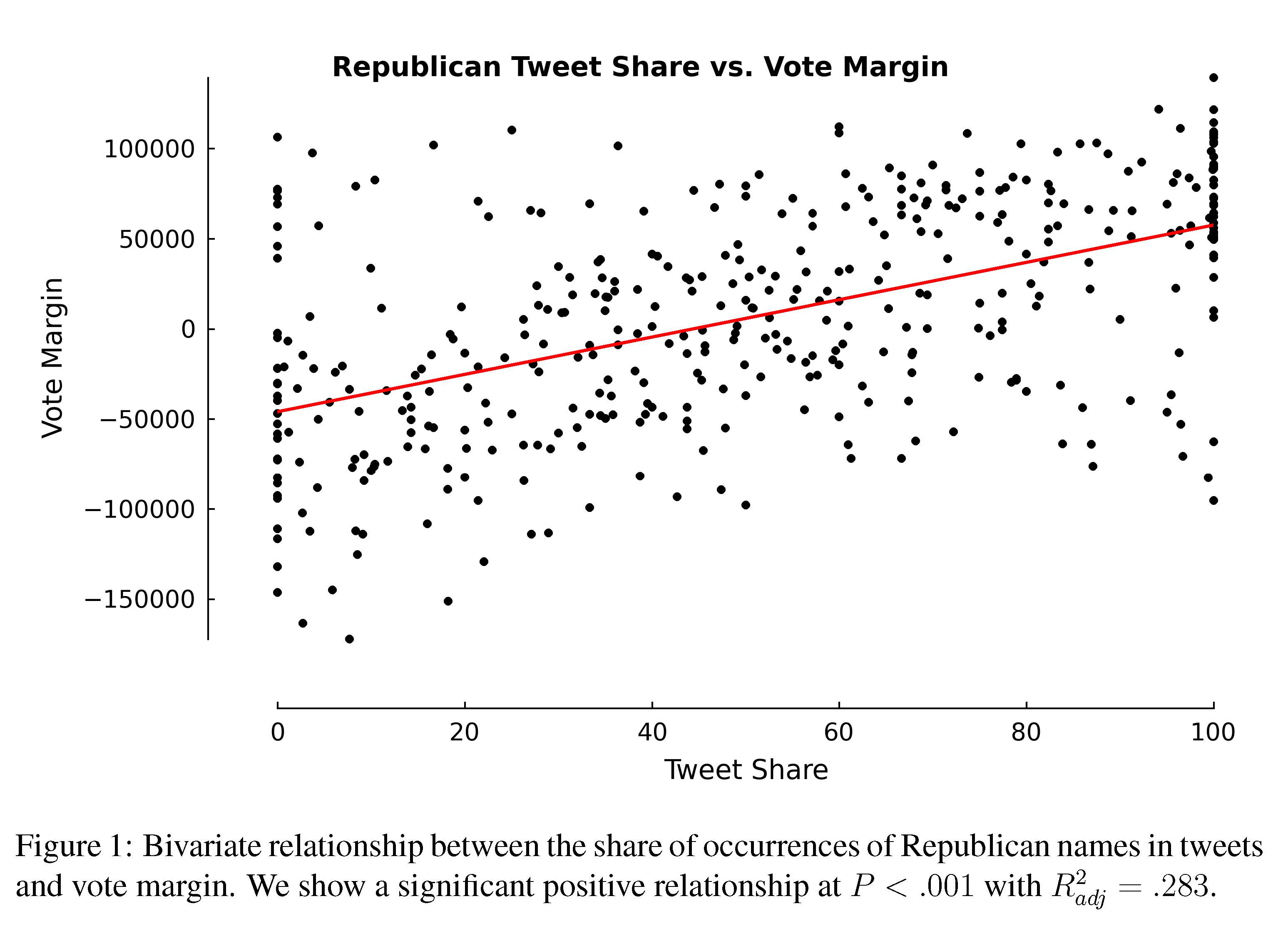
Spend a few minutes reading the Rojas editorial and skimming the actual paper. Be sure to consider Figure 1 and Table 1 carefully, and address the following questions.
- working paper: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2235423
- published in PLoS ONE: http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0079449 DiGrazia J, McKelvey K, Bollen J, Rojas F (2013) More Tweets, More Votes: Social Media as a Quantitative Indicator of Political Behavior. PLoS ONE 8 (11): e79449.
- editorial in The Washington Post by Rojas: http://www.washingtonpost.com/opinions/how-twitter-can-predict-an-election/2013/08/11/35ef885a-0108-11e3-96a8-d3b921c0924a_story.html
- editorial in the Huffington Post by Linkins: http://www.huffingtonpost.com/2013/08/14/twitter-predict-elections_n_3755326.html
- editorial blog by Gelman: http://andrewgelman.com/2013/04/24/the-tweets-votes-curve/

Statistics Hat
- Write a sentence summarizing the findings of the paper.
- Discuss Figure 1 with your neighbor. What is its purpose? What does it convey? Think critically about this data visualization. What would you do differently?
- should be proportion for the response variable. The bizarre scaling could dramatically change the results
- dots could then be scaled in proportion to the number of tweets
- linear fit may be questionable.
- How would you improve the plot? I.e., annotate it to make it more convincing / communicative? Does it need enhancement?
- Interpret the coefficient of
Republican Tweet Sharein both models shown in Table 1. Be sure to include units. - Discuss with your neighbor the differences between the
Bivariatemodel and theFull Model. Which one do you think does a better job of predicting the outcome of an election? Which one do you think best addresses the influence of tweets on an election?- \(R^2\) is way higher after control variables are included, but duh!
- the full model will likely do a better job of predicting
- Why do you suppose that the coefficient of
Republican Tweet Shareis so much larger in theBivariatemodel? How does this reflect on the influence of tweets in an election?- After controlling for how many Republicans are in the district, most of the effect disappears
- While the coefficient of the main term is still statistically significant, the size of the coefficient
- (155 +/- 43 votes) is of little practical significance
- Do you think the study holds water? Why or why not? What are the shortcomings of this study?
- Not really. First of all, how many of these races are actually competitive? It’s not 406, it’s probably fewer than 100. If you redid the study on that sample, would the tweet share still be statistically significant in the full model?
Data Scientist Hat
Imagine that your boss, who does not have advanced technical skills or knowledge, asked you to reproduce the study you just read. Discuss the following with your neighbor.
- What steps are necessary to reproduce this study? Be as specific as you can! Try to list the subtasks that you would have to perform.
- What computational tools would you use for each task? Identify all the steps necessary to conduct the study. Could you do it given your current abilities & knowledge? What about the practical considerations? (1) How do you download from Twitter? (2) What is an API (Application Programming Interface), and how does R interface with APIs? (3) How hard is it to store 3.5 billion tweets? (4) How big is a tweet? (5) How do you know which congressional district the person who tweeted was in?
How much storage does it take to download 3.5 billion tweets? = 2000+ Gb = 2+ Tb (your hard drive is likely 1Tb, unless you have a small computer). Can you explain the billions of tweets stored at Indiana University? How would you randomly sample from the database? One tweet is about 2/3 of a Kb.


Advantages
- Cheap
- Can measure any political race (not just the wealthy ones).
Disadvantages
- Is it really reflective of the voting populace? Who would it bias toward?
- Does simple mention of a candidate always reflect voting patterns? When wouldn’t it?
- Margin of error of 2.7%. How is that number typically calculated in a poll? Note: \(2 \cdot \sqrt{(1/2)(1/2)/1000} = 0.0316\).
- Tweets feel more free in terms of what you are able to say - is that a good thing or a bad thing with respect to polling?
- Can’t measure any demographic information.
What could be done differently?
- Gelman: look only at close races
- Gelman: “It might make sense to flip it around and predict twitter mentions given candidate popularity. That is, rotate the graph 90 degrees, and see how much variation there is in tweet shares for elections of different degrees of closeness.”
- Gelman: “And scale the size of each dot to the total number of tweets for the two candidates in the election.”
- Gelman: Make the data publicly available so that others can try to reproduce the results
Tweeting and R
The twitter analysis requires a twitter password, and sorry, I won’t give you mine. If you want to download tweets, follow the instructions at http://stats.seandolinar.com/collecting-twitter-data-introduction/ or maybe one of these: https://www.credera.com/blog/business-intelligence/twitter-analytics-using-r-part-1-extract-tweets/ and http://davetang.org/muse/2013/04/06/using-the-r_twitter-package/ and ask me if you have any questions.
1.6 Reflection questions
What tools help make an analysis reproducible? And in what ways do each of the tools help?
What do the following mean: scriptability, literate programming, version control?
What is the difference between R and R Studio?
What does it mean to “render” a Quarto file?
What does it mean for the data to be “tidy”?
1.7 Ethics considerations
Why does it matter if an analysis is reproducible?
-
Which of these can data science do and which can’t it do?
- model the data
- establish causation
- find patterns and visualizations in large datasets
- represent data that isn’t there
Is everything measurable? What about the “best” college? Is there a single continuum on which every college can be ranked? What other examples can you come up with that don’t really make sense to measure in a single number?
Much of this content was inspired by great educators who provide open source materials for educational use. Many thanks to Mine Çetinkaya-Rundel (Duke), Ben Baumer (Smith), Brianna Heggeseth (Macalester), Leslie Myint (Macalester), Paul Roback (St Olaf), and Ciaran Evans (Wake Forest) for sharing their materials.↩︎