6 Logistic Regression
6.1 Motivation for Logistic Regression
During investigation of the US space shuttle Challenger disaster, it was learned that project managers had judged the probability of mission failure to be 0.00001, whereas engineers working on the project had estimated failure probability at 0.005. The difference between these two probabilities, 0.00499 was discounted as being too small to worry about. Is a different picture provided by considering odds? How is it interpreted?
The logistic regression model is a generalized linear model. That is, a linear model as a function of the expected value of the response variable. We can now model binary response variables. \[\begin{align} GLM: g(E[Y | X]) = \beta_0 + \beta_1 X \end{align}\] where \(g(\cdot)\) is the link function. For logistic regression, we use the logit link function: \[\begin{align} \mbox{logit} (p) = \ln \bigg( \frac{p}{1-p} \bigg) \end{align}\]
6.1.0.1 Surviving Third-degree Burns
These data refer to 435 adults who were treated for third-degree burns by the University of Southern California General Hospital Burn Center. The patients were grouped according to the area of third-degree burns on the body (measured in square cm). In the table below are recorded, for each midpoint of the groupings log(area +1), the number of patients in the corresponding group who survived, and the number who died from the burns. (Fan, Heckman, and Wand 1995)
| log(area+1) midpoint | survived | died | prop surv |
|---|---|---|---|
| 1.35 | 13 | 0 | 1 |
| 1.60 | 19 | 0 | 1 |
| 1.75 | 67 | 2 | 0.971 |
| 1.85 | 45 | 5 | 0.900 |
| 1.95 | 71 | 8 | 0.899 |
| 2.05 | 50 | 20 | 0.714 |
| 2.15 | 35 | 31 | 0.530 |
| 2.25 | 7 | 49 | 0.125 |
| 2.35 | 1 | 12 | 0.077 |
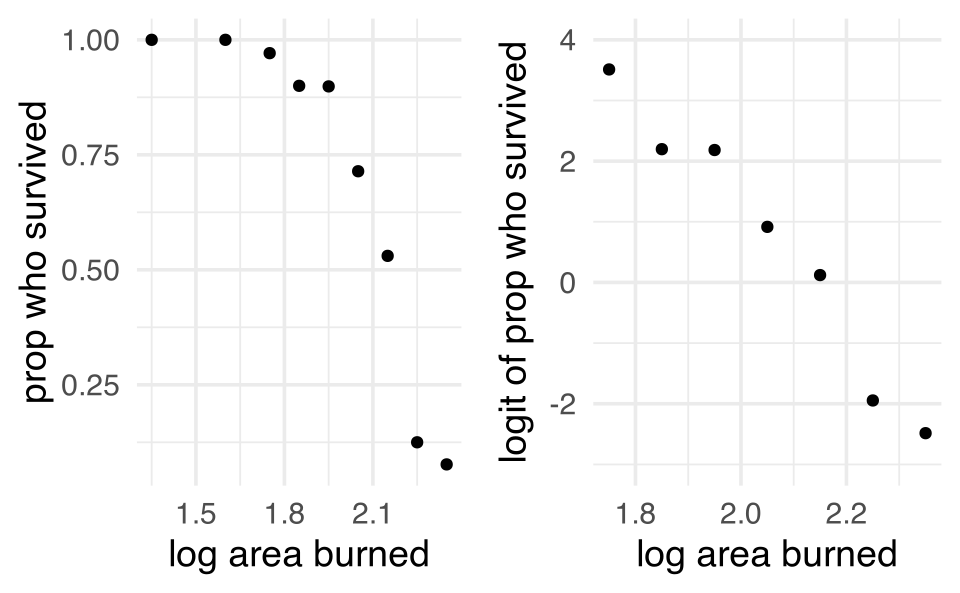
We can see that the logit transformation linearizes the relationship.
A first idea might be to model the relationship between the probability of success (that the patient survives) and the explanatory variable log(area +1) as a simple linear regression model. However, the scatterplot of the proportions of patients surviving a third-degree burn against the explanatory variable shows a distinct curved relationship between the two variables, rather than a linear one. It seems that a transformation of the data is in place.
The functional form relating x and the probability of success looks like it could be an S shape. But we’d have to do some work to figure out what the form of that S looks like. Below I’ve given some different relationships between x and the probability of success using \(\beta_0\) and \(\beta_1\) values that are yet to be defined. Regardless, we can see that by tuning the functional relationship of the S curve, we can get a good fit to the data.
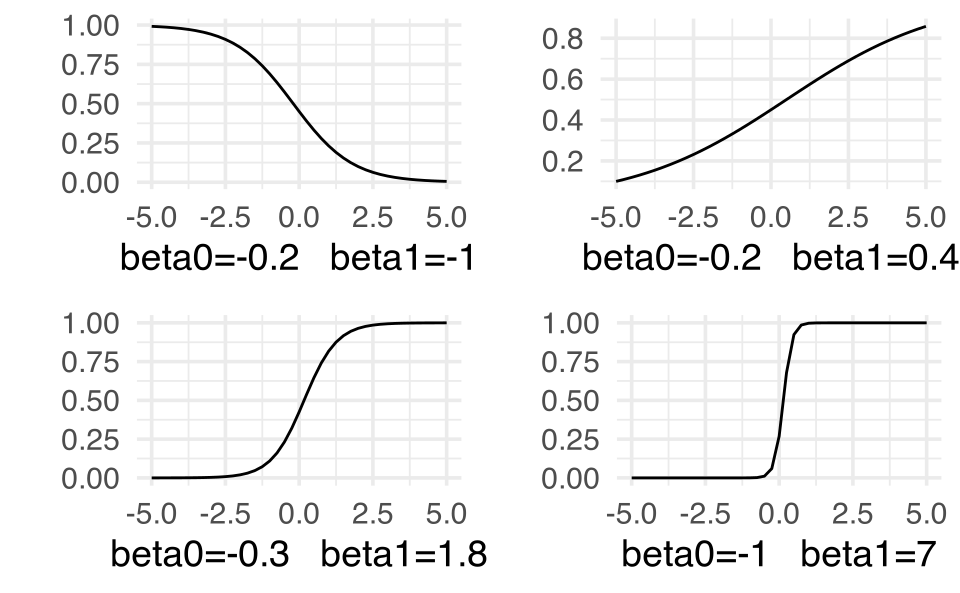
S-curves ( y = exp(linear) / (1+exp(linear)) ) for a variety of different parameter settings. Note that the x-axis is some continuous variable x while the y-axis is the probability of success at that value of x. More on this as we move through this model.
Why doesn’t linear regression work here?
- The response isn’t normal
- The response isn’t linear (until we transform)
- The predicted values go outside the bounds of (0,1)
- Note: it does work to think about values inside (0,1) as probabilities
6.1.1 The logistic model
Instead of trying to model the using linear regression, let’s say that we consider the relationship between the variable \(x\) and the probability of success to be given by the following generalized linear model. (The logistic model is just one model, there isn’t anything magical about it. We do have good reasons for how we defined it, but that doesn’t mean there aren’t other good ways to model the relationship.)
\[\begin{align} p(x) = \frac{e^{\beta_0 + \beta_1 x}}{1+e^{\beta_0 + \beta_1 x}} \end{align}\] Where \(p(x)\) is the probability of success (here surviving a burn). \(\beta_1\) still determines the direction and slope of the line. \(\beta_0\) now determines the location (median survival).
Note 1 What is the probability of success for a patient with covariate of \(x = -\beta_0 / \beta_1\)?
\[\begin{align} x &= - \beta_0 / \beta_1\\ \beta_0 + \beta_1 x &= 0\\ e^{0} &= 1\\ p(-\beta_0 / \beta_1) &= p(x) = 0.5 \end{align}\] (for a given \(\beta_1,\) \(\beta_0\) determines the median survival value)Note 2 If \(x=0,\) \[\begin{align} p(0) = \frac{e^{\beta_0}}{1+e^{\beta_0}} \end{align}\] \(x=0\) can often be thought of as the baseline condition, and the probability at \(x=0\) takes the place of thinking about the intercept in a linear regression.
Note 3
\[\begin{align} 1 - p(x) = \frac{1}{1+e^{\beta_0 + \beta_1 x}} \end{align}\]
gives the probability of failure. \[\begin{align} \frac{p(x)}{1-p(x)} = e^{\beta_0 + \beta_1 x} \end{align}\]
gives the odds of success. \[\begin{align} \ln \bigg( \frac{p(x)}{1-p(x)} \bigg) = \beta_0 + \beta_1 x \end{align}\]
gives the \(\ln\) odds of success .Note 4 Every type of generalized linear model has a link function. Ours is called the logit. The link is the relationship between the response variable and the linear function in x. \[\begin{align} \mbox{logit}(\star) = \ln \bigg( \frac{\star}{1-\star} \bigg) \ \ \ \ 0 < \star < 1 \end{align}\]
6.1.1.1 model conditions
Just like in linear regression, our Y response is the only random component.
\[\begin{align} y &= \begin{cases} 1 & \mbox{ died}\\ 0 & \mbox{ survived} \end{cases} \end{align}\]
\[\begin{align} Y &\sim \mbox{Bernoulli}(p)\\ P(Y=y) &= p^y(1-p)^{1-y} \end{align}\]
When each person is at risk for a different covariate (i.e., explanatory variable), they each end up with a different probability of success. \[\begin{align} Y_i \sim \mbox{Bernoulli} \bigg( p(x_i) = \frac{e^{\beta_0 + \beta_1 x_i}}{1+ e^{\beta_0 + \beta_1 x_i}}\bigg) \end{align}\]
- independent trials
- success / failure
- probability of success is constant for a particular \(X.\)
- \(E[Y|x] = p(x)\) is given by the logistic function
6.1.1.2 interpreting coefficients
Let’s say the log odds of survival for given observed (log) burn areas \(x\) and \(x+1\) are: \[\begin{align} \mbox{logit}(p(x)) &= \beta_0 + \beta_1 x\\ \mbox{logit}(p(x+1)) &= \beta_0 + \beta_1 (x+1)\\ \beta_1 &= \mbox{logit}(p(x+1)) - \mbox{logit}(p(x))\\ &= \ln \bigg(\frac{p(x+1)}{1-p(x+1)} \bigg) - \ln \bigg(\frac{p(x)}{1-p(x)} \bigg)\\ &= \ln \bigg( \frac{p(x+1) / [1-p(x+1)]}{p(x) / [1-p(x)]} \bigg)\\ e^{\beta_1} &= \bigg( \frac{p(x+1) / [1-p(x+1)]}{p(x) / [1-p(x)]} \bigg)\\ \end{align}\]
\(e^{\beta_1}\) is the odds ratio for dying associated with a one unit increase in x. [\(\beta_1\) is the change in log-odds associated with a one unit increase in x.
\[\begin{align} \mbox{logit} (\hat{p}) = 22.708 - 10.662 \cdot \ln(\mbox{ area }+1). \end{align}\]
(Suppose we are interested in comparing the odds of surviving third-degree burns for patients with burns corresponding to log(area +1)= 1.90, and patients with burns corresponding
to log(area +1)= 2.00. The odds ratio \(\hat{OR}_{1.90, 2.00}\) is given by
\[\begin{align}
\hat{OR}_{1.90, 2.00} = e^{-10.662 \cdot (1.90-2.00)} = e^{1.0662} = 2.904
\end{align}\]
That is, the odds of survival for a patient with log(area+1)= 1.90 is 2.9 times higher than the odds of survival for a patient with log(area+1)= 2.0.)
What about the RR (relative risk) or difference in risks? It won’t be constant for a given \(X,\) so it must be calculated as a function of \(X.\)
6.1.2 constant OR, varying RR
The previous model specifies that the OR is constant for any value of \(X\) which is not true about RR. Using the burn data, convince yourself that the RR isn’t constant. Try computing the RR at 1.5 versus 2.5, then again at 1 versus 2. \[\begin{align} \mbox{logit} (\hat{p}) &= 22.708 - 10.662 \cdot \ln(\mbox{ area }+1)\\ \hat{p}(x) &= \frac{e^{22.708 - 10.662 x}}{1+e^{22.708 - 10.662 x}}\\ \end{align}\]
\[\begin{align} \hat{p}(1) &= 0.9999941\\ \hat{p}(1.5) &= 0.9987889\\ \hat{p}(2) &= 0.7996326\\ \hat{p}(2.5) &= 0.01894664\\ \hat{RR}_{1, 2} &= 1.250567\\ \hat{RR}_{1.5, 2.5} &= 52.71587\\ \end{align}\]
\[\begin{align} \hat{RR} &= \frac{\frac{e^{b_0 + b_1 x}}{1+e^{b_0 + b_1 x}}}{\frac{e^{b_0 + b_1 (x+1)}}{1+e^{b_0 + b_1 (x+1)}}}\\ &= \frac{\frac{e^{b_0}e^{b_1 x}}{1+e^{b_0}e^{b_1 x}}}{\frac{e^{b_0} e^{b_1 x} e^{b_1}}{1+e^{b_0}e^{b_1 x} e^{b_1}}}\\ &= \frac{1+e^{b_0}e^{b_1 x}e^{b_1}}{e^{b_1}(1+e^{b_0}e^{b_1 x})}\\ \end{align}\] (see log-linear model below, 6.1.2.1 )
6.1.2.1 Alternative strategies for binary outcomes
It is quite common to have binary outcomes (response variable) in the medical literature. However, the logit link (logistic regression) is only one of a variety of models that we can use. We see above that the logistic model imposes a constant OR for any value of \(X\) (and not a constant RR).
-
complementary log-log
The complementary log-log model is used when you have a rate of, for example, infection, model by instances of contact (based on a Poisson model). \[\begin{align} p(k) &= 1-(1-\lambda)^k\\ \ln[ - \ln (1-p(k))] &= \ln[-\ln(1-\lambda)] + \ln(k)\\ \ln[ - \ln (1-p(k))] &= \beta_0 + 1 \cdot \ln(k)\\ \ln[ - \ln (1-p(k))] &= \beta_0 + \beta_1 x\\ p(x) &= 1 - \exp [ -\exp(\beta_0 + \beta_1 x) ] \end{align}\] -
linear
The excess (or additive) risk model can modeled by using simple linear regression: \[\begin{align} p(x) &= \beta_0 + \beta_1 x \end{align}\] which we have already seen is problematic for a variety of reasons. However, any unit increase in \(x\) gives a \(\beta_1\) increase in the risk (for all values of \(x.)\) -
log-linear
As long as we do not have a case-control study, we can model the risk using a log-linear model. \[\begin{align} \ln (p(x)) = \beta_0 + \beta_1 x \end{align}\] The regression coefficient, \(\beta_1,\) has the interpretation of the logarithm of the relative risk associated with a unit increase in \(x.\) Although many software programs will fit this model, it may present numerical difficulties because of the constraint that the sum of terms on the right-hand side must be no greater than zero for the results to make sense (due to the constraint that the outcome probability p(x) must be in the interval [0,1]). As a result, convergence of standard fitting algorithms may be unreliable in some cases.
6.2 Estimating coefficients in logistic regression
6.2.1 Maximum Likelihood Estimation
Recall how we estimated the coefficients for linear regression. The values of \(b_0\) and \(b_1\) are those that minimize the residual sum of squares: \[\begin{align} RSS &= \sum_i (Y_i - \hat{Y}_i)^2\\ &= \sum_i (Y_i - (\beta_0 + \beta_1 X_i))^2 \end{align}\] That is, we take derivatives with respect to both \(\beta_0\) and \(\beta_1,\) set them equal to zero (take second derivatives to ensure minimums), and solve to get \(b_0\) and \(b_1.\) It turns out that we’ve also maximized the normal likelihood. \[\begin{align} L(\underline{y} | \beta_0, \beta_1, \underline{x}) &= \prod_i \frac{1}{\sqrt{2 \pi \sigma^2}} e^{(y_i - \beta_0 - \beta_1 x_i)^2 / 2 \sigma^2}\\ &= \bigg( \frac{1}{2 \pi \sigma^2} \bigg)^{n/2} e^{\sum_i (y_i - \beta_0 - \beta_1 x_i)^2 / 2 \sigma^2}\\ \end{align}\]
What does that even mean? Likelihood? Maximizing the likelihood? WHY??? The likelihood is the probability distribution of the data given specific values of the unknown parameters.
Consider a toy example where you take a sample of size 4 from a binary population (e.g., flipping a coin that has probability heads of \(p)\) and get: failure, success, failure, failure (FSFF).
Would you guess \(p=0.47??\) No, you would guess \(p=0.25...\) you maximized the likelihood of seeing your data. \[\begin{align} P(FSFF| p) &= p^1 (1-p)^{4-1}\\ P(FSFF | p = 0.90) &= 0.0009 \\ P(FSFF | p = 0.75) &= 0.0117 \\ P(FSFF | p = 0.50) &= 0.0625\\ P(FSFF | p = 0.47) &= 0.070\\ P(FSFF | p = 0.25) &= 0.105\\ P(FSFF | p = 0.15) &= 0.092\\ P(FSFF | p = 0.05) &= 0.043\\ \end{align}\]
Think about the example as a set of independent binary responses, \(Y_1, Y_2, \ldots Y_n.\) Since each observed response is independent and follows the Bernoulli distribution, the probability of a particular outcome can be found as: \[\begin{align} P(Y_1=y_1, Y_2=y_2, \ldots, Y_n=y_n) &= P(Y_1=y_1) P(Y_2 = y_2) \cdots P(Y_n = y_n)\\ &= p^{y_1}(1-p)^{1-y_1} p^{y_2}(1-p)^{1-y_2} \cdots p^{y_n}(1-p)^{1-y_n}\\ &= p^{\sum_i y_i} (1-p)^{\sum_i (1-y_i)}\\ \end{align}\] where \(y_1, y_2, \ldots, y_n\) represents a particular observed series of 0 or 1 outcomes and \(p\) is a probability \(0 \leq p \leq 1.\) Once \(y_1, y_2, \ldots, y_n\) have been observed, they are fixed values. Maximum likelihood estimates are functions of sample data that are derived by finding the value of \(p\) that maximizes the likelihood functions.
To maximize the likelihood, we use the natural log of the likelihood (because we know we’ll get the same answer): \[\begin{align} \ln L(p) &= \ln \Bigg(p^{\sum_i y_i} (1-p)^{\sum_i (1-y_i)} \Bigg)\\ &= \sum_i y_i \ln(p) + (n- \sum_i y_i) \ln (1-p)\\ \frac{ \partial \ln L(p)}{\partial p} &= \sum_i y_i \frac{1}{p} + (n - \sum_i y_i) \frac{-1}{(1-p)} = 0\\ 0 &= (1-p) \sum_i y_i + p (n-\sum_i y_i) \\ \hat{p} &= \frac{ \sum_i y_i}{n} \end{align}\]
Using the logistic regression model makes the likelihood substantially more complicated because the probability of success changes for each individual. Recall: \[\begin{align} p_i = p(x_i) &= \frac{e^{\beta_0 + \beta_1 x_i}}{1+e^{\beta_0 + \beta_1 x_i}} \end{align}\] which gives a likelihood of: \[\begin{align} L(\beta_0,\beta_1) &= \prod_i \Bigg( \frac{e^{\beta_0 + \beta_1 x_i}}{1+e^{\beta_0 + \beta_1 x_i}} \Bigg)^{y_i} \Bigg(1-\frac{e^{\beta_0 + \beta_1 x_i}}{1+e^{\beta_0 + \beta_1 x_i}} \Bigg)^{(1- y_i)} \\ \mbox{and a log likelihood of}: &\\ \ln L(\beta_0, \beta_1) &= \sum_i y_i \ln\Bigg( \frac{e^{\beta_0 + \beta_1 x_i}}{1+e^{\beta_0 + \beta_1 x_i}} \Bigg) + (1- y_i) \ln \Bigg(1-\frac{e^{\beta_0 + \beta_1 x_i}}{1+e^{\beta_0 + \beta_1 x_i}} \Bigg)\\ \end{align}\]
To find \(b_0\) and \(b_1\) we actually use numerical optimization techniques to maximize \(L(\beta_0,\beta_1)\) (…Because using calculus won’t provide closed form solutions. Try taking derivatives and setting them equal to zero. What happens?)
Why use maximum likelihood estimates?
- Estimates are essentially unbiased.
- We can estimate the SE (Wald estimates via Fisher Information).
- The estimates have low variability.
- The estimates have an approximately normal sampling distribution for large sample sizes because they are maximum likelihood estimates.
- Though it is important to realize that we cannot find estimates in closed form.
6.3 Formal Inference
6.3.1 Wald Tests & Intervals
Because we will use maximum likelihood parameter estimates, we can also use large sample theory to find the SEs and consider the estimates to have normal distributions (for large sample sizes). However, (Menard 1995) warns that for large coefficients, standard error is inflated, lowering the Wald statistic (chi-square) value. (Agresti 1996) states that the likelihood-ratio test is more reliable for small sample sizes than the Wald test.
\[\begin{align} z = \frac{b_1 - \beta_1}{SE(b_1)} \end{align}\]
glm(burnresp~burnexpl, data = burnglm, family="binomial") |>
tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 22.7 2.27 10.0 1.23e-23
#> 2 burnexpl -10.7 1.08 -9.85 6.95e-23Note: Although the model is a Bernoulli model and not really a binomial model (although the Bernoulli is a binomial with \(n=1),\) the way to fit a logistic regression model in R is to use family = "binomial". It just is what it is.
6.3.2 Likelihood Ratio Tests
\(\frac{L(p_0)}{L(\hat{p})}\) gives us a sense of whether the null value or the observed value produces a higher likelihood. Recall: \[\begin{align} L(\hat{\underline{p}}) > L(p_0) \end{align}\] always. [Where \(\hat{\underline{p}}\) is the maximum likelihood estimate for the probability of success (here it will be a vector of probabilities, each based on the same MLE estimates of the linear parameters). ] The above inequality holds because \(\hat{\underline{p}}\) maximizes the likelihood.
We can show that if \(H_0\) is true, \[\begin{align} -2 \ln \bigg( \frac{L(p_0)}{L(\hat{p})} \bigg) \sim \chi^2_1 \end{align}\] If we are testing only one parameter value. More generally, \[\begin{align} -2 \ln \bigg( \frac{\max L_0}{\max L} \bigg) \sim \chi^2_\nu \end{align}\] where \(\nu\) is the number of extra parameters we estimate using the unconstrained likelihood (as compared to the constrained null likelihood).
Example 6.1 Consider a data set with 147 people. 49 got cancer and 98 didn’t. Let’s test whether the true proportion of people who get cancer is \(p=0.25.\) \[\begin{align} H_0:& p=0.25\\ H_a:& p \ne 0.25\\ \hat{p} &= \frac{49}{147}\\ -2 \ln \bigg( \frac{L(p_0)}{L(\hat{p})} \bigg) &= -2 [ \ln (L(p_0)) - \ln(L(\hat{p}))]\\ &= -2 \Bigg[ \ln \bigg( (0.25)^{\sum y_i} (0.75)^{n-\sum y_i} \bigg) - \ln \Bigg( \bigg( \frac{\sum y_i}{n} \bigg)^{\sum y_i} \bigg( \frac{(n-\sum y_i)}{n} \bigg)^{n-\sum y_i} \Bigg) \Bigg]\\ &= -2 \Bigg[ \ln \bigg( (0.25)^{49} (0.75)^{98} \bigg) - \ln \Bigg( \bigg( \frac{1}{3} \bigg)^{49} \bigg( \frac{2}{3} \bigg)^{98} \Bigg) \Bigg]\\ &= -2 [ \ln(0.0054) - \ln(0.0697) ] = 5.11\\ P( \chi^2_1 \geq 5.11) &= 0.0238 \end{align}\]
But really, usually likelihood ratio tests are more interesting. In fact, usually, we use them to test whether the coefficients are zero:
\[\begin{align} H_0: & \beta_1 =0\\ H_a: & \beta_1 \ne 0\\ p_0 &= \frac{e^{\hat{b}_0}}{1 + e^{\hat{b}_0}} \end{align}\] where \(\hat{b}_0\) is the MLE from the logistic regression model which does not contain any explanatory variable, \(x.\)
Important note: \[\begin{align} \mbox{deviance} = \mbox{constant} - 2 \ln(\mbox{likelihood}) \end{align}\] That is, the difference in log likelihoods will be the opposite difference in deviances: \[\begin{align} \mbox{test stat} &= \chi^2\\ &= -2 \ln \bigg( \frac{L(\mbox{null value(s)})}{L(MLEs)} \bigg)\\ &= -2 [ \ln(L(\mbox{null value(s)}) - \ln(L(MLEs)) ]\\ &= \mbox{deviance}_0 - \mbox{deviance}_{model}\\ &= \mbox{deviance}_{null} - \mbox{deviance}_{residual}\\ &= \mbox{deviance}_{reduced} - \mbox{deviance}_{full}\\ \end{align}\]
glm(burnresp~burnexpl, data = burnglm, family="binomial") |>
glance()
#> # A tibble: 1 × 8
#> null.deviance df.null logLik AIC BIC deviance df.residual nobs
#> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <int> <int>
#> 1 525. 434 -168. 339. 347. 335. 433 435\[\begin{align} \mbox{test stat} &= G\\ &= -2 \ln \bigg( \frac{L(\mbox{null value(s)})}{L(MLEs)} \bigg)\\ &= -2 [ \ln(L(\mbox{null value(s)}) - \ln(L(MLEs)) ]\\ &= \mbox{deviance}_0 - \mbox{deviance}_{model}\\ &= \mbox{deviance}_{null} - \mbox{deviance}_{residual}\\ &= \mbox{deviance}_{reduced} - \mbox{deviance}_{full}\\ \end{align}\]
So, the LRT here is (see columns of null deviance and deviance):
\[\begin{align}
G &= 525.39 - 335.23 = 190.16\\
p-value &= P(\chi^2_1 \geq 190.16) = 0
\end{align}\]
6.3.2.1 modeling categorical predictors with multiple levels
Example 6.2 Snoring A study was undertaken to investigate whether snoring is related to a heart disease. In the survey, 2484 people were classified according to their proneness to snoring (never, occasionally, often, always) and whether or not they had the heart disease.
| Variable | Description |
|---|---|
| disease (response variable) | Binary variable: having disease=1, |
| not having disease=0 | |
| snoring (explanatory variable) | Categorical variable indicating level of snoring |
| (never=1, occasionally=2, often=3 and always=4) |
Source: (Norton and Dunn 1985)
\[\begin{align} X_1 = \begin{cases} 1 & \text{for occasionally} \\ 0 & \text{otherwise} \\ \end{cases} X_2 = \begin{cases} 1 & \text{for often} \\ 0 & \text{otherwise} \\ \end{cases} X_3 = \begin{cases} 1 & \text{for always} \\ 0 & \text{otherwise} \\ \end{cases} \end{align}\]
Our new model becomes: \[\begin{align} \mbox{logit}(p) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \beta_3 X_3 \end{align}\]
We can use the drop-in-deviance test to test the effect of any or all of the parameters (of which there are now four) in the model.
See the birdnest example, 6.8
6.4 Multiple Logistic Regression
6.4.1 Interaction
Another worry when building models with multiple explanatory variables has to do with variables interacting. That is, for one level of a variable, the relationship of the main predictor on the response is different.
Example 6.3 Consider a simple linear regression model on number of hours studied and exam grade. Then add class year to the model. There would probably be a different slope for each class year in order to model the two variables most effectively. For simplicity, consider only first year students and seniors.
\[\begin{align} E[\mbox{grade seniors}| \mbox{hours studied}] &= \beta_{0s} + \beta_{1s} \mbox{hrs}\\ E[\mbox{grade first years}| \mbox{hours studied}] &= \beta_{0f} + \beta_{1f} \mbox{hrs}\\ E[\mbox{grade}| \mbox{hours studied}] &= \beta_{0} + \beta_{1} \mbox{hrs} + \beta_2 I(\mbox{year=senior}) + \beta_{3} \mbox{hrs} I(\mbox{year = senior})\\ \beta_{0f} &= \beta_{0}\\ \beta_{0s} &= \beta_0 + \beta_2\\ \beta_{1f} &= \beta_1\\ \beta_{1s} &= \beta_1 + \beta_3 \end{align}\]
Why do we need the \(I(\mbox{year=seniors})\) variable?
Definition 6.1 Interaction means that the effect of an explanatory variable on the outcome differs according to the level of another explanatory variable. (Not the case with age on smoking and lung cancer above. With the smoking example, age is a significant variable, but it does not interact with lung cancer.)
Example 6.4 The Heart and Estrogen/progestin Replacement Study (HERS) is a randomized, double-blind, placebo-controlled trial designed to test the efficacy and safety of estrogen plus progestin therapy for prevention of recurrent coronary heart disease (CHD) events in women. The participants are postmenopausal women with a uterus and with CHD. Each woman was randomly assigned to receive one tablet containing 0.625 mg conjugated estrogens plus 2.5 mg medroxyprogesterone acetate daily or an identical placebo. The results of the first large randomized clinical trial to examine the effect of hormone replacement therapy (HRT) on women with heart disease appeared in JAMA in 1998 (Hulley et al. 1998).
The Heart and Estrogen/Progestin Replacement Study (HERS) found that the use of estrogen plus progestin in postmenopausal women with heart disease did not prevent further heart attacks or death from coronary heart disease (CHD). This occurred despite the positive effect of treatment on lipoproteins: LDL (bad) cholesterol was reduced by 11 percent and HDL (good) cholesterol was increased by 10 percent.
The hormone replacement regimen also increased the risk of clots in the veins (deep vein thrombosis) and lungs (pulmonary embolism). The results of HERS are surprising in light of previous observational studies, which found lower rates of CHD in women who take postmenopausal estrogen.
Data available at: http://www.biostat.ucsf.edu/vgsm/data/excel/hersdata.xls For now, we will try to predict whether the individuals had a pre-existing medical condition (other than CHD, self reported), medcond. We will use the variables age, weight, diabetes and drinkany.
glm(medcond ~ age, data = HERS, family="binomial") |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -1.60 0.401 -4.00 0.0000624
#> 2 age 0.0162 0.00597 2.71 0.00664
glm(medcond ~ age + weight, data = HERS, family="binomial") |> tidy()
#> # A tibble: 3 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -2.17 0.496 -4.37 0.0000124
#> 2 age 0.0189 0.00613 3.09 0.00203
#> 3 weight 0.00528 0.00274 1.93 0.0542
glm(medcond ~ age+diabetes, data = HERS, family="binomial") |> tidy()
#> # A tibble: 3 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -1.89 0.408 -4.64 0.00000349
#> 2 age 0.0185 0.00603 3.07 0.00217
#> 3 diabetes 0.487 0.0882 5.52 0.0000000330
glm(medcond ~ age*diabetes, data = HERS, family="binomial") |> tidy()
#> # A tibble: 4 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -2.52 0.478 -5.26 0.000000141
#> 2 age 0.0278 0.00707 3.93 0.0000844
#> 3 diabetes 2.83 0.914 3.10 0.00192
#> 4 age:diabetes -0.0354 0.0137 -2.58 0.00986
glm(medcond ~ age*drinkany, data = HERS, family="binomial") |> tidy()
#> # A tibble: 4 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -0.991 0.511 -1.94 0.0526
#> 2 age 0.00885 0.00759 1.17 0.244
#> 3 drinkany -1.44 0.831 -1.73 0.0833
#> 4 age:drinkany 0.0168 0.0124 1.36 0.175Write out a few models by hand, does any of the significance change with respect to interaction? Does the interpretation change with interaction? In the last model, we might want to remove all the age information. Age seems to be less important than drinking status. How do we decide? How do we model?
6.4.2 Simpson’s Paradox
Simpson’s paradox is when the association between two variables is opposite the partial association between the same two variables after controlling for one or more other variables.
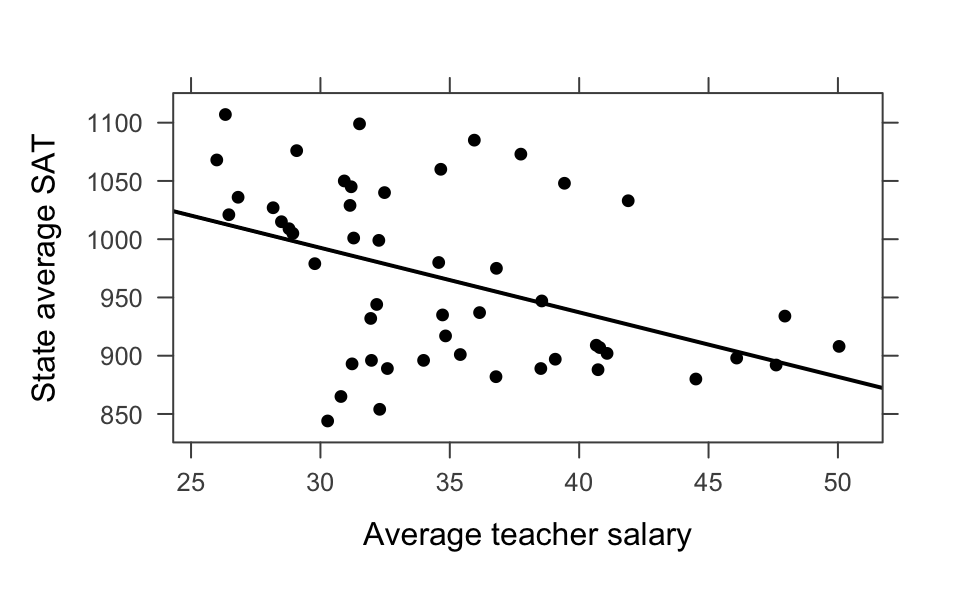
Example 6.5 Back to linear regression to consider Simpson’s Paradox in the wild. Consider data on SAT scores across different states with information on educational expenditure. The correlation between SAT score and average teacher salary is negative with the combined data. However, SAT score and average teacher salary is positive after controlling for the fraction of students who take the exam. The fewer students who take the exam, the higher the SAT score. That’s because states whose public universities encourage the ACT have SAT-takers who are leaving the state for college (with their higher SAT scores).
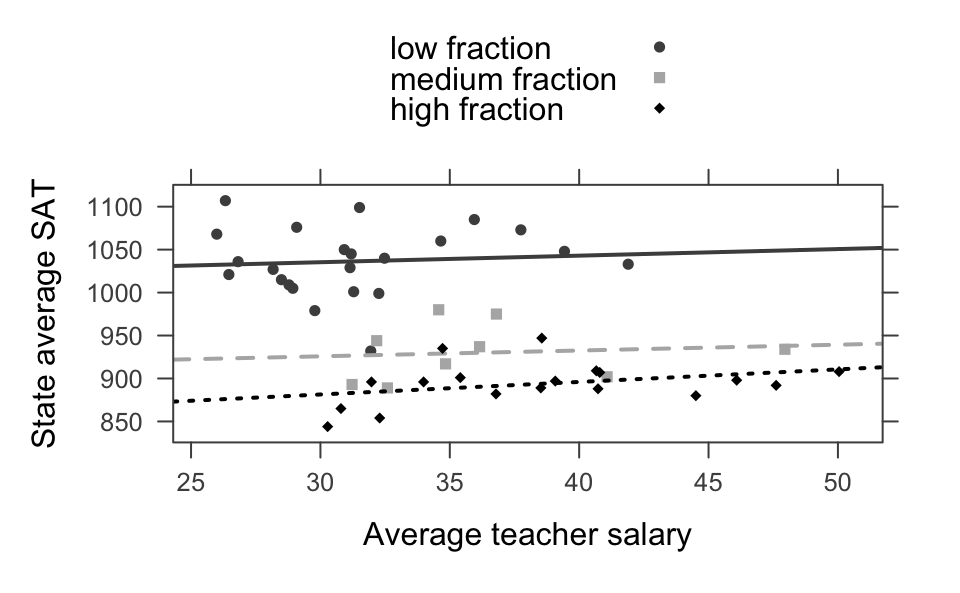
head(SAT)
#> state expend ratio salary frac verbal math sat fracgrp
#> 1 Alabama 4.41 17.2 31.1 8 491 538 1029 low fraction
#> 2 Alaska 8.96 17.6 48.0 47 445 489 934 medium fraction
#> 3 Arizona 4.78 19.3 32.2 27 448 496 944 medium fraction
#> 4 Arkansas 4.46 17.1 28.9 6 482 523 1005 low fraction
#> 5 California 4.99 24.0 41.1 45 417 485 902 medium fraction
#> 6 Colorado 5.44 18.4 34.6 29 462 518 980 medium fraction
lm(sat ~ salary, data=SAT) |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 1159. 57.7 20.1 5.13e-25
#> 2 salary -5.54 1.63 -3.39 1.39e- 3
lm(sat ~ salary + frac, data=SAT) |> tidy()
#> # A tibble: 3 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 988. 31.9 31.0 6.20e-33
#> 2 salary 2.18 1.03 2.12 3.94e- 2
#> 3 frac -2.78 0.228 -12.2 4.00e-16
lm(sat ~ salary * frac, data=SAT) |> tidy()
#> # A tibble: 4 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 1082. 54.4 19.9 3.00e-24
#> 2 salary -0.720 1.70 -0.424 6.73e- 1
#> 3 frac -5.03 1.09 -4.62 3.15e- 5
#> 4 salary:frac 0.0648 0.0308 2.11 4.05e- 2
lm(sat ~ salary + fracgrp, data=SAT) |> tidy()
#> # A tibble: 4 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 1002. 31.8 31.5 8.55e-33
#> 2 salary 1.09 0.988 1.10 2.76e- 1
#> 3 fracgrpmedium fraction -112. 14.3 -7.82 5.46e-10
#> 4 fracgrphigh fraction -150. 12.8 -11.7 2.09e-15
lm(sat ~ salary * fracgrp, data=SAT) |> tidy()
#> # A tibble: 6 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 1012. 55.8 18.1 4.85e-22
#> 2 salary 0.768 1.77 0.435 6.65e- 1
#> 3 fracgrpmedium fraction -107. 103. -1.04 3.03e- 1
#> 4 fracgrphigh fraction -175. 79.2 -2.21 3.27e- 2
#> 5 salary:fracgrpmedium fraction -0.0918 2.93 -0.0313 9.75e- 1
#> 6 salary:fracgrphigh fraction 0.692 2.28 0.303 7.63e- 1Example 6.6 Consider the example on smoking and 20-year mortality (case) from section 3.4 of Regression Methods in Biostatistics, pg 52-53. The study represents women participating in a health survey in Whickham, England in 1972-1972 with follow-up 20 years later (Vanderpump et al. 1995). Mortality was recorded as the response variable and self-reported smoking and age (both given in the original study) as the explanatory variables.
| age | test | smoker | nonsmoker | prob smoke | odds smoke | empirical OR |
|---|---|---|---|---|---|---|
| all | case | 139 | 230 | 0.377 | 0.604 | 0.685 |
| control | 443 | 502 | 0.469 | 0.882 | ||
| 18-44 | case | 61 | 32 | 0.656 | 1.906 | 1.627 |
| control | 375 | 320 | 0.540 | 1.172 | ||
| 45-64 | case | 34 | 66 | 0.340 | 0.515 | 1.308 |
| control | 50 | 127 | 0.282 | 0.394 | ||
| 65+ | case | 44 | 132 | 0.250 | 0.333 | 1.019 |
| control | 18 | 55 | 0.247 | 0.327 |
What we see is that the vast majority of the controls were young, and they had a high rate of smoking. A good chunk of the cases were older, and the rate of smoking was substantially lower in the oldest group. However, within each group, the cases were more likely to smoke than the controls.
After adjusting for age, smoking is no longer significant. But more importantly, age is a variable that reverses the effect of smoking on cancer - Simpson’s Paradox. The effect is not due to the observational nature of the study, and so it is important to adjust for possible influential variables regardless of the study at hand.
What would it mean to adjust for age in this context? It means that we have to include it in the model:
glm( death ~ smoke, family="binomial") |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -0.781 0.0796 -9.80 1.10e-22
#> 2 smoke -0.379 0.126 -3.01 2.59e- 3
glm( death ~ age, family="binomial") |> tidy()
#> # A tibble: 3 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -0.571 0.125 -4.56 5.01e- 6
#> 2 ageold 1.45 0.187 7.75 9.00e-15
#> 3 ageyoung -1.44 0.167 -8.63 6.02e-18
glm( death ~ smoke + age, family="binomial") |> tidy()
#> # A tibble: 4 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -0.668 0.135 -4.96 7.03e- 7
#> 2 smoke 0.312 0.154 2.03 4.25e- 2
#> 3 ageold 1.47 0.188 7.84 4.59e-15
#> 4 ageyoung -1.52 0.173 -8.81 1.26e-18
glm( death ~ smoke * age, family="binomial") |> tidy()
#> # A tibble: 6 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -0.655 0.152 -4.31 1.61e- 5
#> 2 smoke 0.269 0.269 0.999 3.18e- 1
#> 3 ageold 1.53 0.221 6.93 4.29e-12
#> 4 ageyoung -1.65 0.240 -6.88 6.00e-12
#> 5 smoke:ageold -0.251 0.420 -0.596 5.51e- 1
#> 6 smoke:ageyoung 0.218 0.355 0.614 5.40e- 1Using the additive model above: \[\begin{align} \mbox{logit} (p(x_1, x_2) ) &= \beta_0 + \beta_1 x_1 + \beta_2 x_2\\ OR &= \mbox{odds dying if } (x_1, x_2) / \mbox{odds dying if } (x_1^*, x_2^*) = \frac{e^{\beta_0 + \beta_1 x_1 + \beta_2 x_2}}{e^{\beta_0 + \beta_1 x_1^* + \beta_2 x_2^*}}\\ x_1 &= \begin{cases} 0 & \mbox{ don't smoke}\\ 1 & \mbox{ smoke}\\ \end{cases}\\ x_2 &= \begin{cases} \mbox{young} & \mbox{18-44 years old}\\ \mbox{middle} & \mbox{45-64 years old}\\ \mbox{old} & \mbox{65+ years old}\\ \end{cases} \end{align}\] where we are modeling the probability of 20-year mortality using smoking status and age group.
Note 1: We can see from above that the coefficients for each variable are significantly different from zero. That is, the variables are important in predicting odds of survival.
Note 2: We can see that smoking becomes less significant as we add age into the model. That is because age and smoking status are so highly associated (think of the coin example).
Note 3: We can estimate any of the OR (of dying for smoke vs not smoke) from the given coefficients:
\[\begin{align}
\mbox{simple model} &\\
\mbox{overall OR} &= e^{-0.37858 } = 0.6848332\\
& \\
\mbox{additive model} &\\
\mbox{young, middle, old OR} &= e^{ 0.3122} = 1.3664\\
& \\
\mbox{interaction model} &\\
\mbox{young OR} &= e^{0.2689 + 0.2177} = 1.626776\\
\mbox{middle OR} &= e^{0.2689} = 1.308524\\
\mbox{old OR} &= e^{0.2689 + -0.2505} = 1.018570\\
\end{align}\]
What does it mean that the interaction terms are not significant in the last model?
6.5 Multicollinearity
Multicollinearity happens when the explanatory variables in a model are correlated. If explanatory variables are correlated, great care needs to be taken in interpreting the coefficients because the idea of “holding all other variables constant” does not make sense. The following example illustrates the point.
Example 6.7 Consider the following data set collected from church offering plates in 62 consecutive Sundays. Also noted is whether there was enough change to buy a candy bar for $1.25.
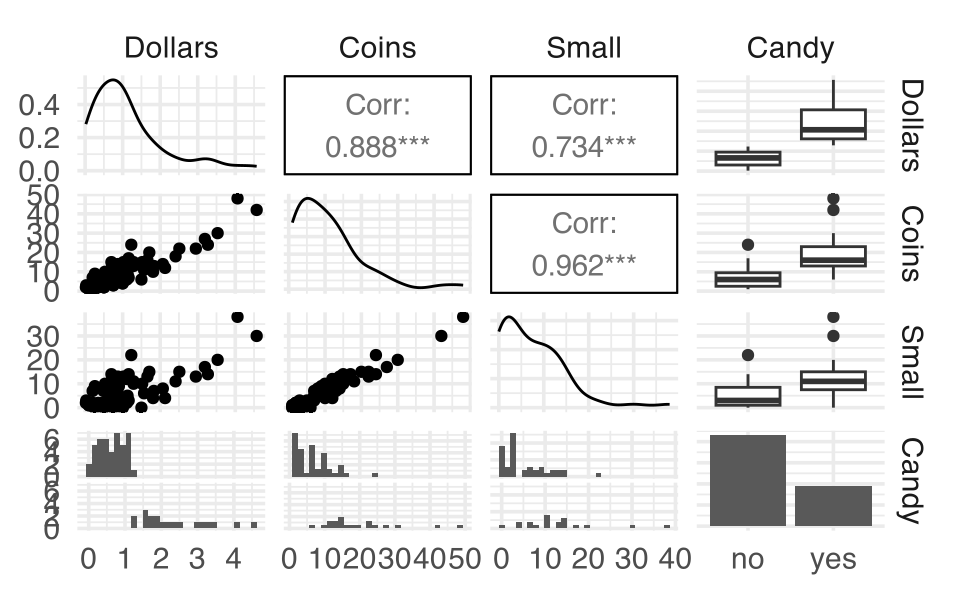
glm(Candy ~ Coins, data = Offering, family="binomial") |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -4.14 0.996 -4.16 0.0000321
#> 2 Coins 0.286 0.0772 3.70 0.000213
glm(Candy ~ Small, data = Offering, family="binomial") |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -2.33 0.585 -3.98 0.0000693
#> 2 Small 0.184 0.0576 3.19 0.00142
glm(Candy ~ Coins + Small, data = Offering, family="binomial") |> tidy()
#> # A tibble: 3 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -17.0 7.80 -2.18 0.0296
#> 2 Coins 3.49 1.75 1.99 0.0461
#> 3 Small -3.04 1.57 -1.93 0.0531Notice that the directionality of the low coins changes when it is included in the model that already contains the number of coins total. Lesson of the story: be very very very careful interpreting coefficients when you have multiple explanatory variables.
6.6 Model Building
Example 6.8 Suppose that you have to take an exam that covers 100 different topics, and you do not know any of them. The rules, however, state that you can bring two classmates as consultants. Suppose also that you know which topics each of your classmates is familiar with. If you could bring only one consultant, it is easy to figure out who you would bring: it would be the one who knows the most topics (the variable most associated with the answer). Let’s say this is Sage who knows 85 topics. With two consultants you might choose Sage first, and for the second option, it seems reasonable to choose the second most knowledgeable classmate (the second most highly associated variable), for example Bruno, who knows 75 topics.
The problem with this strategy is that it may be that the 75 subjects Bruno knows are already included in the 85 that Sage knows, and therefore, Bruno does not provide any knowledge beyond that of Sage.
A better strategy is to select the second not by considering what they know regarding the entire agenda, but by looking for the person who knows more about the topics that the first does not know (the variable that best explains the residual of the equation with the variables entered). It may even happen that the best pair of consultants are not the most knowledgeable, as there may be two that complement each other perfectly in such a way that one knows 55 topics and the other knows the remaining 45, while the most knowledgeable does not complement anybody.
| Individual | # topics | Pair | # topics |
|---|---|---|---|
| Sage | 85 | Sage & Bruno | 95 |
| Bruno | 80 | Sage & Beta | 93 |
| Luna | 55 | Sage & Luna | 92 |
| Beta | 45 | Bruno & Beta | 90 |
| Bruno & Luna | 90 | ||
| Beta & Luna | 100 |
With forward selection, which two are chosen?1
With backward selection, which two are chosen?2
6.6.1 Formal Model Building
We are going to discuss how to add (or subtract) variables from a model. Before we do that, we can define two criteria used for suggesting an optimal model.
AIC: Akaike’s Information Criteria = \(-2 \ln\) likelihood + \(2p\)
BIC: Bayesian Information Criteria = \(-2 \ln\) likelihood \(+p \ln(n)\)
Both techniques suggest choosing a model with the smallest AIC and BIC value; both adjust for the number of parameters in the model and are more likely to select models with fewer variables than the drop-in-deviance test.
6.6.1.1 Stepwise Regression
As done previously, we can add and remove variables based on the deviance. Recall, when comparing two nested models, the differences in the deviances can be modeled by a \(\chi^2_\nu\) variable where \(\nu = \Delta p.\)
Consider the HERS data described in your book (page 30); variable description also given on the book website http://www.epibiostat.ucsf.edu/biostat/vgsm/data/hersdata.codebook.txt
For now, we will try to predict whether the individuals had a medical condition, medcond (defined as a pre-existing and self-reported medical condition). We will use the variables age, weight, diabetes and drinkany.
glm(medcond ~ age, data = HERS, family="binomial") |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -1.60 0.401 -4.00 0.0000624
#> 2 age 0.0162 0.00597 2.71 0.00664
glm(medcond ~ age + weight, data = HERS, family="binomial") |> tidy()
#> # A tibble: 3 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -2.17 0.496 -4.37 0.0000124
#> 2 age 0.0189 0.00613 3.09 0.00203
#> 3 weight 0.00528 0.00274 1.93 0.0542
glm(medcond ~ age+diabetes, data = HERS, family="binomial") |> tidy()
#> # A tibble: 3 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -1.89 0.408 -4.64 0.00000349
#> 2 age 0.0185 0.00603 3.07 0.00217
#> 3 diabetes 0.487 0.0882 5.52 0.0000000330
glm(medcond ~ age*diabetes, data = HERS, family="binomial") |> tidy()
#> # A tibble: 4 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -2.52 0.478 -5.26 0.000000141
#> 2 age 0.0278 0.00707 3.93 0.0000844
#> 3 diabetes 2.83 0.914 3.10 0.00192
#> 4 age:diabetes -0.0354 0.0137 -2.58 0.00986
glm(medcond ~ age*drinkany, data = HERS, family="binomial") |> tidy()
#> # A tibble: 4 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -0.991 0.511 -1.94 0.0526
#> 2 age 0.00885 0.00759 1.17 0.244
#> 3 drinkany -1.44 0.831 -1.73 0.0833
#> 4 age:drinkany 0.0168 0.0124 1.36 0.175
glm(medcond ~ age + weight + diabetes + drinkany, data = HERS, family="binomial") |> tidy()
#> # A tibble: 5 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -1.87 0.505 -3.72 0.000203
#> 2 age 0.0184 0.00620 2.96 0.00304
#> 3 weight 0.00143 0.00285 0.500 0.617
#> 4 diabetes 0.432 0.0924 4.68 0.00000288
#> 5 drinkany -0.253 0.0835 -3.03 0.00248
glm(medcond ~ age , data = HERS, family="binomial") |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -1.60 0.401 -4.00 0.0000624
#> 2 age 0.0162 0.00597 2.71 0.00664
glm(medcond ~ weight , data = HERS, family="binomial") |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -0.769 0.198 -3.88 0.000106
#> 2 weight 0.00339 0.00267 1.27 0.204
glm(medcond ~ diabetes , data = HERS, family="binomial") |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -0.652 0.0467 -13.9 3.18e-44
#> 2 diabetes 0.468 0.0878 5.34 9.55e- 8
glm(medcond ~ drinkany, data = HERS, family="binomial") |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -0.398 0.0498 -8.00 1.26e-15
#> 2 drinkany -0.330 0.0818 -4.04 5.46e- 5Forward Selection
One idea is to start with an empty model and adding the best available variable at each iteration, checking for needs for transformations. We should also look at interactions which we might suspect. However, looking at all possible interactions (if only 2-way interactions, we could also consider 3-way interactions etc.), things can get out of hand quickly.
- We start with the response variable versus all variables and find the best predictor. If there are too many, we might just look at the correlation matrix. However, we may miss out of variables that are good predictors but aren’t linearly related. Therefore, if its possible, a scatter plot matrix would be best.
- We locate the best variable, and regress the response variable on it.
- If the variable seems to be useful, we keep it and move on to looking for a second.
- If not, we stop.
Forward Stepwise Selection
This method follows in the same way as Forward Regression, but as each new variable enters the model, we check to see if any of the variables already in the model can now be removed. This is done by specifying two values, \(\alpha_e\) as the \(\alpha\) level needed to enter the model, and \(\alpha_l\) as the \(\alpha\) level needed to leave the model. We require that \(\alpha_e<\alpha_l,\) otherwise, our algorithm could cycle, we add a variable, then immediately decide to delete it, continuing ad infinitum. This is bad.
- We start with the empty model, and add the best predictor, assuming the p-value associated with it is smaller than \(\alpha_e.\)
- Now, we find the best of the remaining variables, and add it if the p-value is smaller than \(\alpha_e.\) If we add it, we also check to see if the first variable can be dropped, by calculating the p-value associated with it (which is different from the first time, because now there are two variables in the model). If its p-value is greater than \(\alpha_l,\) we remove the variable.
- We continue with this process until there are no more variables that meet either requirements. In many situations, this will help us from stopping at a less than desirable model.
How do you choose the \(\alpha\) values? If you set \(\alpha_e\) to be very small, you might walk away with no variables in your model, or at least not many. If you set it to be large, you will wander around for a while, which is a good thing, because you will explore more models, but you may end up with variables in your model that aren’t necessary.
Backward Selection
- Start with the full model including every term (and possibly every interaction, etc.).
- Remove the variable that is least significant (biggest p-value) in the model.
- Continue removing variables until all variables are significant at the chosen \(\alpha\) level.
glm(medcond ~ (age + diabetes + weight + drinkany)^2, data = HERS, family="binomial") |> glance()
#> # A tibble: 1 × 8
#> null.deviance df.null logLik AIC BIC deviance df.residual nobs
#> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <int> <int>
#> 1 3643. 2758 -1793. 3608. 3673. 3586. 2748 2759
glm(medcond ~ age + diabetes + weight + drinkany, data = HERS, family="binomial") |> glance()
#> # A tibble: 1 × 8
#> null.deviance df.null logLik AIC BIC deviance df.residual nobs
#> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <int> <int>
#> 1 3643. 2758 -1797. 3605. 3634. 3595. 2754 2759
glm(medcond ~ age + diabetes + drinkany, data = HERS, family="binomial") |> tidy()
#> # A tibble: 4 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -1.72 0.413 -4.17 0.0000300
#> 2 age 0.0176 0.00605 2.90 0.00369
#> 3 diabetes 0.442 0.0895 4.94 0.000000786
#> 4 drinkany -0.252 0.0834 -3.01 0.00257- The big model (with all of the interaction terms) has a deviance of 3585.7; the additive model has a deviance of 3594.8.
\[\begin{align} G &= 3594.8 - 3585.7= 9.1\\ p-value &= P(\chi^2_6 \geq 9.1)= 1 - pchisq(9.1, 6) = 0.1680318 \end{align}\] We cannot reject the null hypothesis, so we know that we don’t need the 6 interaction terms. Next we will check whether we need weight.
- The additive model has a deviance of 3594.8; the model without weight is 3597.3.
\[\begin{align} G &= 3597.3 - 3594.8 =2.5\\ p-value &= P(\chi^2_1 \geq 2.5)= 1 - pchisq(2.5, 1) = 0.1138463 \end{align}\] We cannot reject the null hypothesis, so we know that we don’t need the weight in the model either.
6.6.2 Getting the Model Right
In terms of selecting the variables to model a particular response, four things can happen:
- The logistic regression model is correct!
- The logistic regression model is underspecified.
- The logistic regression model contains extraneous variables.
- The logistic regression model is overspecified.
Underspecified
A regression model is underspecified if it is missing one or more important predictor variables. Being underspecified is the worst case scenario because the model ends up being biased and predictions are wrong for virtually every observation. (Think about Simpson’s Paradox and the need for interaction.)
Extraneous
The third type of variable situation comes when extra variables are included in the model but the variables are neither related to the response nor are they correlated with the other explanatory variables. Generally, extraneous variables are not so problematic because they produce models with unbiased coefficient estimators, unbiased predictions, and unbiased variance estimates. The worst thing that happens is that the error degrees of freedom is lowered which makes confidence intervals wider and p-values bigger (lower power). Also problematic is that the model becomes unnecessarily complicated and harder to interpret.
Overspecified
When a model is overspecified, there are one or more redundant variables. That is, the variables contain the same information as other variables (i.e., are correlated!). As we’ve seen, correlated variables cause trouble because they inflate the variance of the coefficient estimates. With correlated variables it is still possible to get unbiased prediction estimates, but the coefficients themselves are so variable that they cannot be interpreted (nor can inference be easily performed).
Generally: the idea is to use a model building strategy with some criteria (\(\chi^2\)-tests, AIC, BIC, ROC, AUC) to find the middle ground between an underspecified model and an overspecified model.
6.6.2.1 One Model Building Strategy
Taken from https://onlinecourses.science.psu.edu/stat501/node/332.
Model building is definitely an “art.” Unsurprisingly, there are many approaches to model building, but here is one strategy, consisting of seven steps, that is commonly used when building a regression model.
The first step
Decide on the type of model that is needed in order to achieve the goals of the study. In general, there are five reasons one might want to build a regression model. They are:
- For predictive reasons - that is, the model will be used to predict the response variable from a chosen set of predictors.
- For theoretical reasons - that is, the researcher wants to estimate a model based on a known theoretical relationship between the response and predictors. For example, there may be a known physical relationship (with parameters to esimate) or a differential equation that models state changes.
- For control purposes - that is, the model will be used to control a response variable by manipulating the values of the predictor variables.
- For inferential reasons - that is, the model will be used to explore the strength of the relationships between the response and the predictors.
- For data summary reasons - that is, the model will be used merely as a way to summarize a large set of data by a single equation.
The second step
Decide which explanatory variables and response variable on which to collect the data. Collect the data.
The third step
Explore the data. That is:
- On a univariate basis, check for outliers, gross data errors, and missing values.
- Study bivariate relationships to reveal other outliers, to suggest possible transformations, and to identify possible multicollinearities.
I can’t possibly over-emphasize the data exploration step. There’s not a data analyst out there who hasn’t made the mistake of skipping this step and later regretting it when a data point was found in error, thereby nullifying hours of work.
The fourth step
(The fourth step is very good modeling practice. It gives you a sense of whether or not you’ve overfit the model in the building process.) Randomly divide the data into a training set and a test set:
- The training set, with at least 20 error degrees of freedom (the number of observations is more than 20 larger than the number of variables), is used to estimate the model.
- The test set is used for validation of the fitted model.
The fifth step
Using the training set, identify several candidate models:
- Use best subsets regression.
- Use stepwise regression, forward or backward.
The sixth step
Select and evaluate a few “good” models:
- Select the models based on the criteria we learned, as well as the number and nature of the predictors.
- Evaluate the selected models for violation of the model conditions.
- If none of the models provide a satisfactory fit, try something else, such as collecting more data, identifying different predictors, or formulating a different type of model.
n.b., You could evaluate the few models based on cross-validation of the training data. It isn’t a terrible idea, but you must remind yourself that the training data as a whole were used in the stepwise regression steps, so the cross-validated folds are not independent arbiters of model accuracy.
The seventh and final step
Select the final model:
- A large AUC on the test data is indicative of a good predictive model (for your population of interest).
- Consider false positive rate, false negative rate, outliers, parsimony, relevance, and ease of measurement of predictors.
And, most of all, don’t forget that there is not necessarily only one good model for a given set of data. There might be a few equally satisfactory models.
6.6.2.2 Another Model Building Strategy
![Another strategy for model building. Figure taken from [@sleuth].](figs/sleuthmodelbuild.png)
Figure 6.1: Another strategy for model building. Figure taken from (Ramsey and Schafer 2012).
6.7 Model Assessment
6.7.1 Measures of Association
With logistic regression, we don’t have residuals, so we don’t have a value like \(R^2.\) We can, however, measure whether or not the estimated model is consistent with the data. That is, is the model able to discriminate between successes and failures.
We’d like to choose a model that produces high probabilities of success for those observations where success was recorded and low probabilities of success for those observation where failure was recorded. In other words, we want mostly concordant pairs.
Given a particular pair of observations where one was a success and the other was a failure, if the observation corresponding to a success has a higher probability of success than the observation corresponding to a failure, we call the pair concordant. If the observation corresponding to a success has a lower probability of success than the observation corresponding to a failure, we call the pair discordant. Tied pairs occur when the observed success has the same estimated probability as the observed failure.
6.7.1.1 Back to the burn data 6.1.0.1:
Consider looking at all the pairs of successes and failures in the burn data, we have 308 survivors and 127 deaths = 39,116 pairs of individuals.
One pair of individuals has burn areas of 1.75 and 2.35. \[\begin{align} p(x=1.75) &= \frac{e^{22.7083-10.6624\cdot 1.75}}{1+e^{22.7083 -10.6624\cdot 1.75}} = 0.983\\ p(x=2.35) &= \frac{e^{22.7083-10.6624\cdot 2.35}}{1+e^{22.7083 -10.6624\cdot 2.35}} = 0.087 \end{align}\] The pairs would be concordant if the first individual survived and the second didn’t. The pairs would be discordant if the first individual died and the second survived.
Ideally the model chosen would have a large number of concordant pairs. The following metrics quantify the concordance across the entire model with respect to the observed data:
-
\(D_{xy}\): Somers’ D is the number of concordant pairs minus the number of discordant pairs divided by the total number of pairs.
- gamma: Goodman-Kruskal gamma is the number of concordant pairs minus the number of discordant pairs divided by the total number of pairs excluding ties.
- tau-a: Kendall’s tau-a is the number of concordant pairs minus the number of discordant pairs divided by the total number of pairs of people (including pairs who both survived or both died).
# install.packages(c("Hmisc", "rms"))
library(rms) # you need this line!!
burn.glm <- lrm(burnresp~burnexpl, data = burnglm)
print(burn.glm)
#> Logistic Regression Model
#>
#> lrm(formula = burnresp ~ burnexpl, data = burnglm)
#>
#> Model Likelihood Discrimination Rank Discrim.
#> Ratio Test Indexes Indexes
#> Obs 435 LR chi2 190.15 R2 0.505 C 0.877
#> 0 127 d.f. 1 R2(1,435)0.353 Dxy 0.604
#> 1 308 Pr(> chi2) <0.0001 R2(1,269.8)0.504 gamma 0.824
#> max |deriv| 6e-05 Brier 0.121 tau-a 0.312
#>
#> Coef S.E. Wald Z Pr(>|Z|)
#> Intercept 22.7083 2.2661 10.02 <0.0001
#> burnexpl -10.6624 1.0826 -9.85 <0.0001The summary contains the following elements:
number of observations used in the fit, maximum absolute value of first derivative of log likelihood, model likelihood ratio chi2, d.f., P-value, \(c\) index (area under ROC curve), Somers’ Dxy, Goodman-Kruskal gamma, Kendall’s tau-a rank correlations between predicted probabilities and observed response, the Nagelkerke \(R^2\) index, the Brier score computed with respect to Y \(>\) its lowest level, the \(g\)-index, \(gr\) (the \(g\)-index on the odds ratio scale), and \(gp\) (the \(g\)-index on the probability scale using the same cutoff used for the Brier score).
6.7.2 Receiver Operating Characteristic Curves
Recall that logistic regression can be used to predict the outcome of a binary event (your response variable). A Receiver Operating Characteristic (ROC) Curve is a graphical representation of the relationship between
| Truth | ||||
|---|---|---|---|---|
| positive | negative | |||
| Predicted | positive | true positive | false positive | \(P'\) |
| negative | false negative | true negative | \(N'\) | |
| \(P\) | \(N\) |
- type I error = FP
- type II error = FN
- sensitivity = power = true positive rate (TPR) = TP / P = TP / (TP+FN)
- false positive rate (FPR) = FP / N = FP / (FP + TN)
- specificity = 1 - FPR = TN / (FP + TN)
- accuracy (acc) = (TP+TN) / (P+N)
- positive predictive value (PPV) = precision = TP / (TP + FP)
- negative predictive value (NPV) = TN / (TN + FN)
- false discovery rate = 1 - PPV = FP / (FP + TP)
Example 6.9 For example: consider a pair of individuals with burn areas of 1.75 and 2.35. \[\begin{align} p(x=1.75) &= \frac{e^{22.7083-10.6624\cdot 1.75}}{1+e^{22.7083 -10.6624\cdot 1.75}} = 0.983\\ p(x=2.35) &= \frac{e^{22.7083-10.6624\cdot 2.35}}{1+e^{22.7083 -10.6624\cdot 2.35}} = 0.087\\ x &= \mbox{log area burned} \end{align}\] What value would we assign to 1.75 or 2.35 or 15 for log(area) burned? By changing our cutoff, we can fit an entire curve. We want the curve to be as far in the upper left corner as possible (sensitivity = 1, specificity = 1). Notice that the color band represents the probability cutoff for predicting a ``success.”
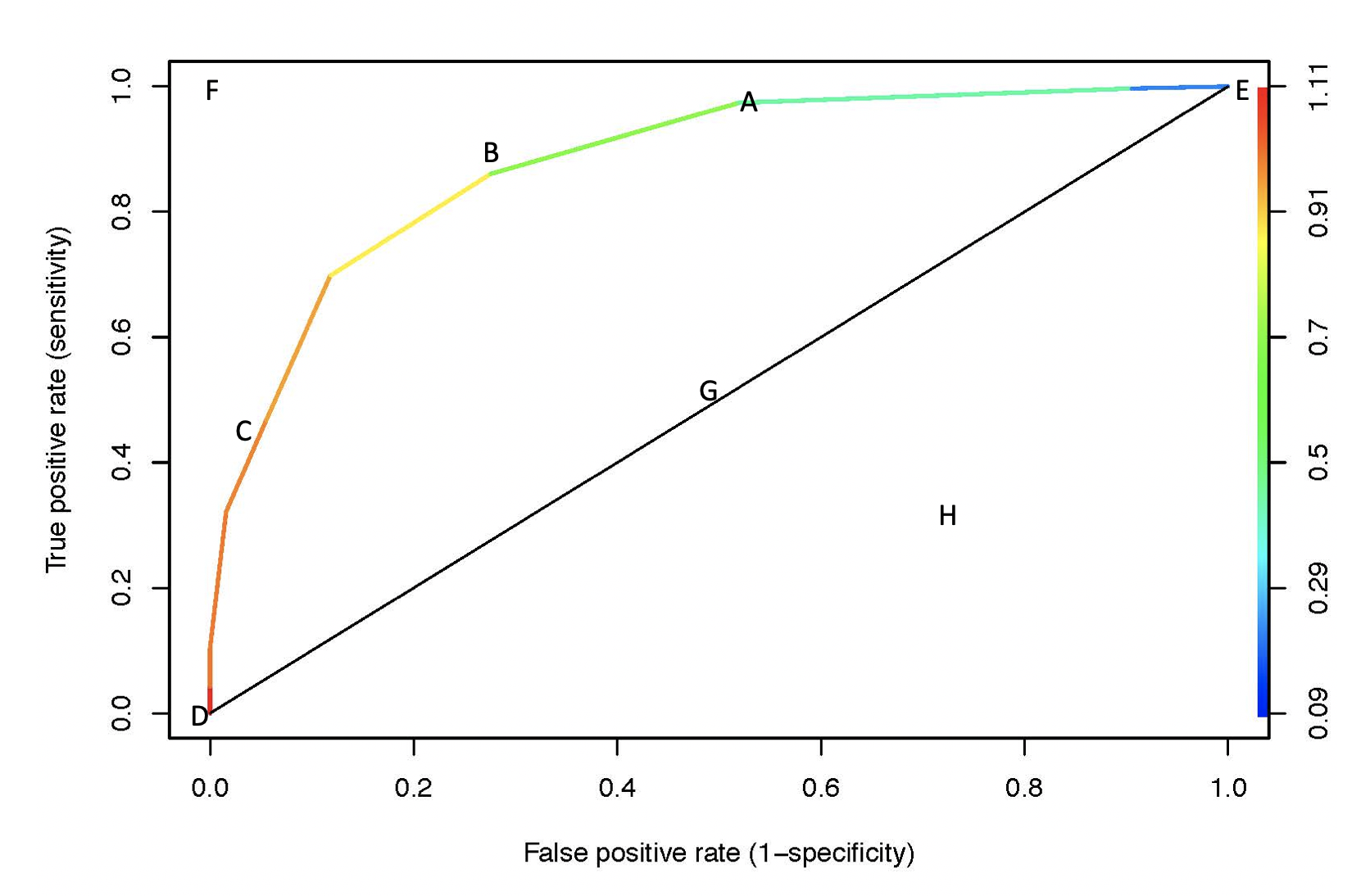
Figure 6.2: ROC curve. Color indicates the probability cutoff used to determine predictions.
A: Let’s say we use prob=0.25 as a cutoff:
| truth | |||
|---|---|---|---|
| yes | no | ||
| predicted | yes | 300 | 66 |
| no | 8 | 61 | |
| 308 | 127 |
\[\begin{align} \mbox{sensitivity} &= TPR = 300/308 = 0.974\\ \mbox{specificity} &= 61 / 127 = 0.480, \mbox{1 - specificity} = FPR = 0.520\\ \end{align}\]
B: Let’s say we use prob=0.7 as a cutoff:
| truth | |||
|---|---|---|---|
| yes | no | ||
| predicted | yes | 265 | 35 |
| no | 43 | 92 | |
| 308 | 127 |
\[\begin{align} \mbox{sensitivity} &= TPR = 265/308 = 0.860\\ \mbox{specificity} &= 92/127 = 0.724, \mbox{1 - specificity} = FPR = 0.276\\ \end{align}\]
C: Let’s say we use prob=0.9 as a cutoff:
| truth | |||
|---|---|---|---|
| yes | no | ||
| predicted | yes | 144 | 7 |
| no | 164 | 120 | |
| 308 | 127 |
\[\begin{align} \mbox{sensitivity} &= TPR = 144/308 = 0.467\\ \mbox{specificity} &= 120/127 = 0.945, \mbox{1 - specificity} = FPR = 0.055\\ \end{align}\]
D: all models will go through (0,0) \(\rightarrow\) predict everything negative, prob=1 as your cutoff
E: all models will go through (1,1) \(\rightarrow\) predict everything positive, prob=0 as your cutoff
F: you have a model that gives perfect sensitivity (no FN!) and specificity (no FP)
G: random guessing. If classifier randomly guess, it should get half the positives correct and half the negatives correct. If it guesses 90% of the positives correctly, it will also guess 90% of the negatives to be positive.
H: is worse than random guessing. Note that the opposite classifier to (H) might be quite good!
6.8 R: Birdnest Example
The following example uses base R modeling to work through different aspects of the logistic regression model.
Length of Bird Nest This example is from problem E1 in your text and includes 99 species of N. American passerine birds. Recall that the response variable is binary and represents whether there is a small opening (closed=1) or a large opening (closed=0) for the nest. The explanatory variable of interest was the length of the bird.
6.8.1 Drop-in-deviance (Likelihood Ratio Test, LRT)
\(\chi^2\): The Likelihood ratio test also tests whether the response is explained by the explanatory variable. We can output the deviance ( = K - 2 * log-likelihood) for both the full (maximum likelihood!) and reduced (null) models. \[\begin{align} G &= 2 \cdot \ln(L(MLE)) - 2 \cdot \ln(L(null))\\ &= \mbox{null (restricted) deviance - residual (full model) deviance}\\ G &\sim \chi^2_{\nu} \ \ \ \mbox{when the null hypothesis is true} \end{align}\] where \(\nu\) represents the difference in the number of parameters needed to estimate in the full model versus the null model.
glm(`Closed?` ~ Length, data = nests, family="binomial") |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 0.457 0.753 0.607 0.544
#> 2 Length -0.0677 0.0425 -1.59 0.112
glm(`Closed?` ~ Length, data = nests, family="binomial") |> glance() |>
print.data.frame(digits=6)
#> null.deviance df.null logLik AIC BIC deviance df.residual nobs
#> 1 119.992 94 -58.4399 120.88 125.987 116.88 93 95
6.8.2 Difference between tidy and augment and glance
Note that tidy contains the same number of rows as the number of coefficients. augment contains the same number of rows as number of observations. glance always has one row (containing overall model information).
glm(`Closed?` ~ Length, data = nests, family="binomial") |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 0.457 0.753 0.607 0.544
#> 2 Length -0.0677 0.0425 -1.59 0.112
glm(`Closed?` ~ Length, data = nests, family="binomial") |> augment()
#> # A tibble: 95 × 9
#> .rownames `Closed?` Length .fitted .resid .hat .sigma .cooksd .std.resid
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 0 20 -0.896 -0.827 0.0137 1.12 0.00288 -0.833
#> 2 2 1 20 -0.896 1.57 0.0137 1.11 0.0173 1.58
#> 3 4 1 20 -0.896 1.57 0.0137 1.11 0.0173 1.58
#> 4 5 1 22.5 -1.07 1.65 0.0202 1.11 0.0305 1.67
#> 5 6 0 18.5 -0.795 -0.863 0.0116 1.12 0.00267 -0.868
#> 6 7 1 17 -0.693 1.48 0.0110 1.12 0.0112 1.49
#> # ℹ 89 more rows
glm(`Closed?` ~ Length, data = nests, family="binomial") |> glance() |>
print.data.frame(digits=6)
#> null.deviance df.null logLik AIC BIC deviance df.residual nobs
#> 1 119.992 94 -58.4399 120.88 125.987 116.88 93 956.8.3 Looking at variables in a few different ways.
Length as a continuous explanatory variable:
glm(`Closed?` ~ Length, data = nests, family="binomial") |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 0.457 0.753 0.607 0.544
#> 2 Length -0.0677 0.0425 -1.59 0.112
glm(`Closed?` ~ Length, data = nests, family="binomial") |> glance() |>
print.data.frame(digits=6)
#> null.deviance df.null logLik AIC BIC deviance df.residual nobs
#> 1 119.992 94 -58.4399 120.88 125.987 116.88 93 95Length as a categorical explanatory variables:
glm(`Closed?` ~ as.factor(Length), data = nests, family="binomial") |> tidy()
#> # A tibble: 34 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 1.96e+1 10754. 1.82e- 3 0.999
#> 2 as.factor(Length)10 9.92e-8 13171. 7.53e-12 1.00
#> 3 as.factor(Length)10.5 9.11e-8 15208. 5.99e-12 1.00
#> 4 as.factor(Length)11 -1.89e+1 10754. -1.75e- 3 0.999
#> 5 as.factor(Length)12 -2.12e+1 10754. -1.97e- 3 0.998
#> 6 as.factor(Length)12.5 9.85e-8 15208. 6.48e-12 1.00
#> # ℹ 28 more rows
glm(`Closed?` ~ as.factor(Length), data = nests, family="binomial") |> glance() |>
print.data.frame(digits=6)
#> null.deviance df.null logLik AIC BIC deviance df.residual nobs
#> 1 119.992 94 -36.8776 141.755 228.587 73.7552 61 95Length plus a few other explanatory variables:
glm(`Closed?` ~ Length + Incubate + Color, data = nests, family="binomial") |> tidy()
#> # A tibble: 4 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) -2.64 2.06 -1.28 0.201
#> 2 Length -0.114 0.0527 -2.17 0.0302
#> 3 Incubate 0.314 0.172 1.82 0.0684
#> 4 Color -0.420 0.609 -0.690 0.490
glm(`Closed?` ~ Length + Incubate + Color, data = nests, family="binomial") |> glance() |>
print.data.frame(digits=6)
#> null.deviance df.null logLik AIC BIC deviance df.residual nobs
#> 1 110.086 87 -51.6633 111.327 121.236 103.327 84 886.8.4 Predicting Response
bird_glm <- glm(`Closed?` ~ Length, data = nests, family="binomial")
bird_glm |> tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 0.457 0.753 0.607 0.544
#> 2 Length -0.0677 0.0425 -1.59 0.112
# predicting the linear part:
# reasonable to use the SE to create CIs
predict(bird_glm, newdata = list(Length = 47), se.fit = TRUE, type = "link")
#> $fit
#> 1
#> -2.72
#>
#> $se.fit
#> [1] 1.3
#>
#> $residual.scale
#> [1] 1
# predicting the probability of success (on the `scale` of the response variable):
# do NOT use the SE to create a CI for the predicted value
# instead, use the SE from `type="link" ` and transform the interval
predict(bird_glm, newdata = list(Length = 47), se.fit = TRUE, type = "response")
#> $fit
#> 1
#> 0.0616
#>
#> $se.fit
#> 1
#> 0.0751
#>
#> $residual.scale
#> [1] 16.8.6 ROC curves
ROC curve for the model on Length only, with no testing / training / cross validated data.
library(plotROC)
nests <- nests |>
mutate(Closed = as.factor(ifelse(`Closed?` == 0, "no",
ifelse(`Closed?` == 1, "yes", `Closed?`))))
bird_glm <- glm(Closed ~ Length, data = nests, family="binomial")
bird_indiv <- bird_glm |>
augment(type.predict = "response")
head(bird_indiv)
#> # A tibble: 6 × 9
#> .rownames Closed Length .fitted .resid .hat .sigma .cooksd .std.resid
#> <chr> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 no 20 0.290 -0.827 0.0137 1.12 0.00288 -0.833
#> 2 2 yes 20 0.290 1.57 0.0137 1.11 0.0173 1.58
#> 3 4 yes 20 0.290 1.57 0.0137 1.11 0.0173 1.58
#> 4 5 yes 22.5 0.256 1.65 0.0202 1.11 0.0305 1.67
#> 5 6 no 18.5 0.311 -0.863 0.0116 1.12 0.00267 -0.868
#> 6 7 yes 17 0.333 1.48 0.0110 1.12 0.0112 1.49
bird_indiv |>
ggplot() +
geom_roc(aes(d = Closed, m = .fitted)) +
geom_abline(intercept = 0, slope = 1)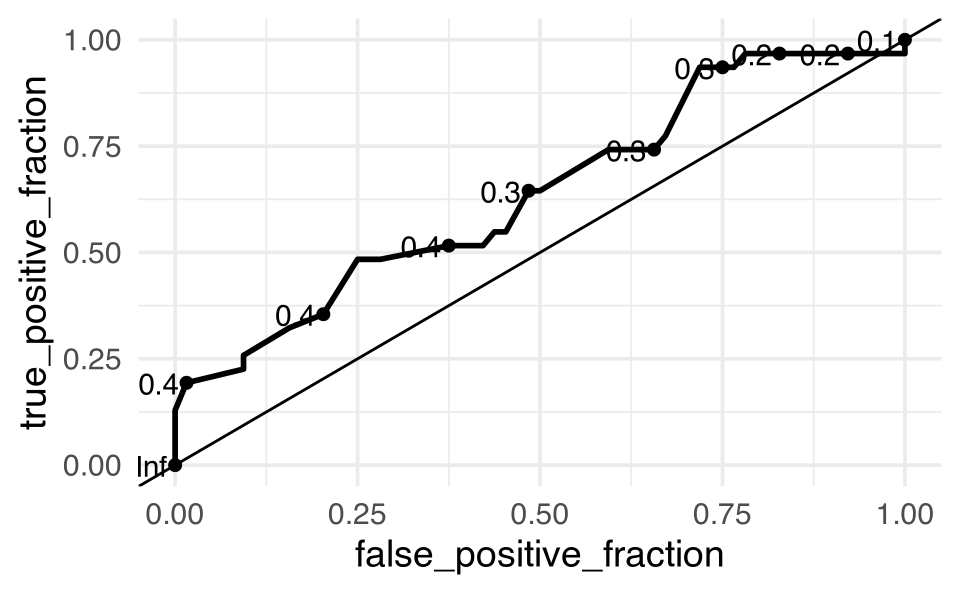
6.8.7 Cross Validation on nest data
Note that the syntax here is slightly different from what we’ve seen previously. From the tidymodels and plotROC packages. See the full explanation in Chapter 7.
library(tidymodels)
library(plotROC)
bird_spec <- logistic_reg() |>
set_engine("glm")
bird_rec <- recipe(
Closed ~ Length + Incubate + Nestling, # formula
data = nests # data for cataloging names and types of variables
)
bird_wflow <- workflow() |>
add_model(bird_spec) |>
add_recipe(bird_rec)
set.seed(47)
bird_folds <- vfold_cv(nests, v = 3)
metrics_interest <- yardstick::metric_set(accuracy, roc_auc,
sensitivity, specificity)
bird_fit_rs <- bird_wflow |>
fit_resamples(bird_folds,
metrics = metrics_interest,
control = control_resamples(save_pred = TRUE))
bird_fit_rs |> collect_metrics()
#> # A tibble: 4 × 6
#> .metric .estimator mean n std_err .config
#> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 accuracy binary 0.755 3 0.00766 Preprocessor1_Model1
#> 2 roc_auc binary 0.815 3 0.00964 Preprocessor1_Model1
#> 3 sensitivity binary 0.842 3 0.0313 Preprocessor1_Model1
#> 4 specificity binary 0.559 3 0.0926 Preprocessor1_Model1
bird_fit_rs |>
unnest(cols = .predictions) |>
ggplot() +
plotROC::geom_roc(aes(m = .pred_yes, d = Closed,
color = id)) +
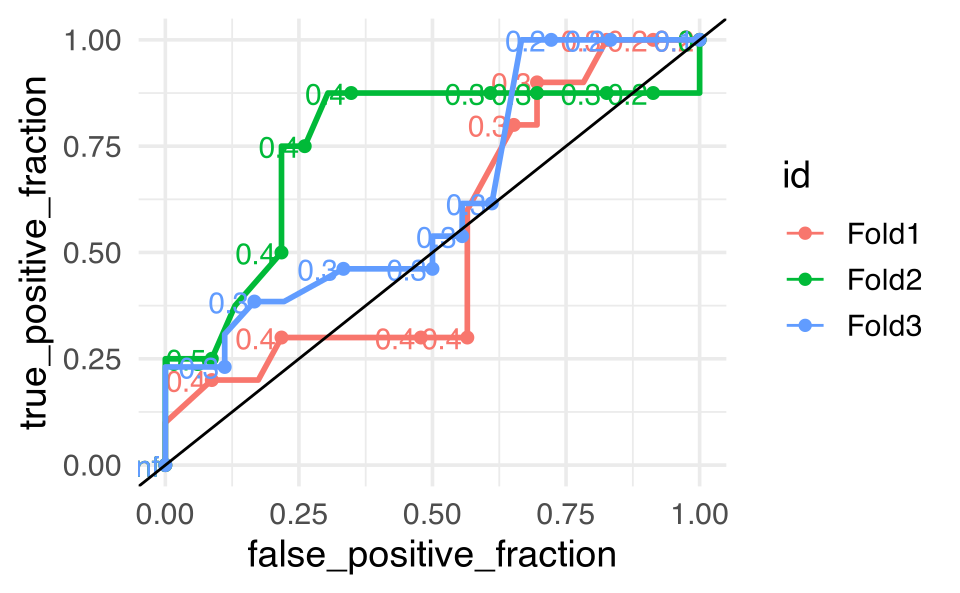
geom_abline(intercept = 0, slope = 1, color = "black")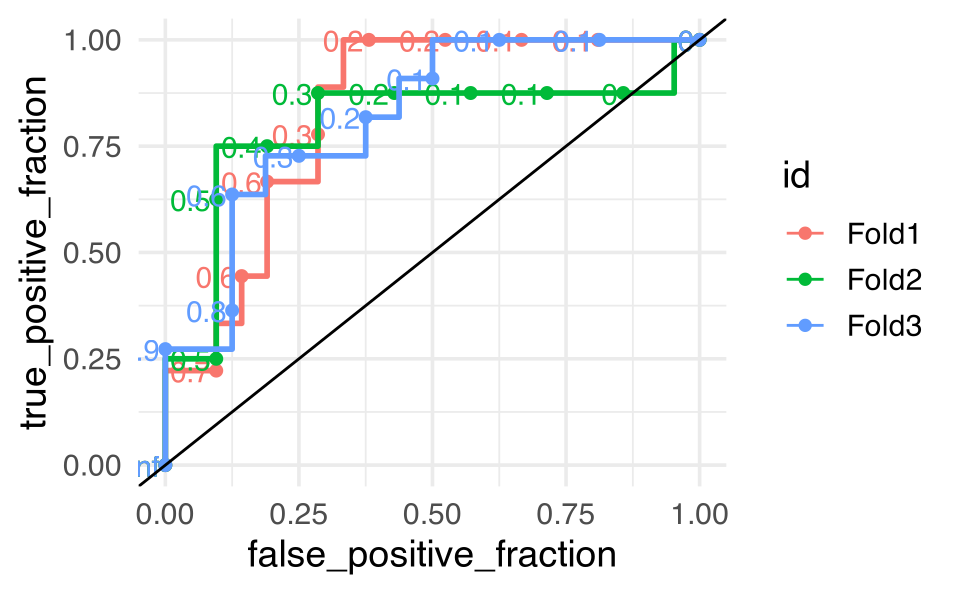
We might try the whole thing over using a model with only one variable. Do the CV values and accuracy get better? No, everything gets worse. But it’s the specificity that we should really pay attention to because it is terrible in the single variable model!
bird_rec_1 <- recipe(
Closed ~ Length, # formula
data = nests # data for cataloging names and types of variables
)
bird_wflow_1 <- workflow() |>
add_model(bird_spec) |>
add_recipe(bird_rec_1)
bird_fit_rs_1 <- bird_wflow_1 |>
fit_resamples(bird_folds,
metrics = metrics_interest,
control = control_resamples(save_pred = TRUE))
bird_fit_rs_1 |> collect_metrics()
#> # A tibble: 4 × 6
#> .metric .estimator mean n std_err .config
#> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 accuracy binary 0.684 3 0.0563 Preprocessor1_Model1
#> 2 roc_auc binary 0.639 3 0.0622 Preprocessor1_Model1
#> 3 sensitivity binary 0.986 3 0.0145 Preprocessor1_Model1
#> 4 specificity binary 0.0833 3 0.0833 Preprocessor1_Model1
bird_fit_rs_1 |>
unnest(cols = .predictions) |>
ggplot() +
plotROC::geom_roc(aes(m = .pred_yes, d = Closed,
color = id)) +
geom_abline(intercept = 0, slope = 1, color = "black")