Below, computer simulations will be used for three main objectives:
Approximate probabilities.
Understand complicated models.
Assess sensitivity of inferential procedures.
We can use simulation studies to understand complex estimators, stochastic processes, etc. Often times, such analytic solutions exist in theory, but are extremely complicated to solve. In particular, as slight variations to the model are added, the simulation is often trivial to change whereas the analytic solution often becomes intractable. Similarly, repeated applications of a procedure (e.g., linear regression) to a scenario (e.g., a dataset, a set of parameters, etc.) can provide important insight into how the procedure varies / behaves.
4.1 Approximating probabilities
Simulation is done to model a scenario which allows us to understand random behavior without actually replicating the entire study multiple times or trying to model the process analytically.
For example, what if you have a keen interest in understanding the probability of getting a single during room draw? Or getting a single on north campus? You wouldn’t actually run room draw thousands of times to find your probability of getting a single room. Similarly, the situation (e.g., room draw) may have too much information (e.g., all the different permutations of integers assigned to groups of 3 or 4 people) to model (easily) in a closed form solution. With a few moderate assumptions (proportion of students in groups of 1, 2, 3, 4; probability of choosing dorm X over dorm Y; random allocation of integers to students; etc.) it is straightforward to simulate the scenario thousands of time and measure the proportion of times your rank (47) will give you the room you want (single in Sontag).
Example Consider the following problem from probability. Two points are selected randomly on a line of length \(L\) so as to be on opposite sides of the midpoint of the line. [In other words, the two points \(X\) and \(Y\) are independent random variables such that \(X\) is uniformly distributed over \((0,L/2)\) and \(Y\) is uniformly distributed over \((L/2, 1)\).] Find the probability that the 3 line segments from \(0\) to \(X\), from \(X\) to \(Y\), and from \(Y\) to \(L\) could be made to form the three sides of a triangle. (Note that three line segments can be made to form a triangle if the length of each of them is less than the sum of the lengths of the others.)
The joint density is: \[ f(x,y) = \begin{cases} \frac{4}{L^2} & 0 \le x \le L/2, \, L/2 \le y \le L \\ 0 & else \end{cases} \]
The three pieces have lengths: \(X\), \(Y- X\) and \(L - Y\). Three conditions need to be satisfied in order that the three pieces form a triangle:
\[\begin{align}
X + (Y- X) &> (L - Y) \Rightarrow Y > L - Y \Rightarrow 2 Y > L \Rightarrow Y > L/2 \\
X + (L-Y ) &> Y - X \Rightarrow 2X + L > 2Y \Rightarrow X + \frac{L}{2} > Y \\
Y + (L - Y) &> X \Rightarrow L > X
\end{align}\]
The first and third conditions are always satisfied, so we just need to find the probability that \(Y\) is below the line \(X + \frac{L}{2}\). The density is the same as in the previous problem, so, as before, we just need to find the area of the region below the line that is within the square \([0, L/2] \times [L/2, L]\), and then multiply it by \(\frac{4}{L^2}\).
Area = \(\displaystyle{ \frac{1}{2}\frac{L}{2}\frac{L}{2} = \frac{L^2}{8} }\).
What happens for different values of \(f(x,y)\)? For example, if \(x\) and \(y\) have Beta(3,47) distributions on [0,.5] and [.5,1]? Simulating the probability in R is quite straightforward. What is the confidence bounds on the point estimates for the probabilities?? [n.b., we could simulate repeatedly to get a sense for the variability of our estimate!]
sticks<-function(){pointx<-runif(1,0,.5)# runif is "random uniform", not "run if"pointy<-runif(1,.5,1)l1<-pointxl2<-pointy-pointxl3<-1-pointymax(l1,l2,l3)>1-max(l1,l2,l3)}sum(replicate(100000, sticks()))/100000
[1] 0.501
sticks_beta<-function(){pointx<-rbeta(1,3, 47)/2# rbeta is random betapointy<-(rbeta(1, 3, 47)+1)/2l1<-pointxl2<-pointy-pointxl3<-1-pointymax(l1,l2,l3)>1-max(l1,l2,l3)}sum(replicate(100000, sticks_beta()))/100000
[1] 0.498
Example Or consider the problem where the goal is to estimate \(E(X)\) where \(X=\max \{ k: \sum_{i=1}^k U_i < 1 \}\) and \(U_i\) are uniform(0,1). The simulation problem is quite straightforward. Look carefully at the pieces. How are they broken down into steps? Notice that the steps go from inside out.
Set k (the number of random numbers) equal to zero. And the running sum to zero.
Generate a uniform random variable.
Add the random variable to the running sum. Repeat steps 1 and 2 until the sum is larger than 1.
Figure out how many random variables were needed to get the sum larger than 1.
Repeat the entire process many times so as to account for variability in the simulation.
Use the law of large numbers to conclude that the average of the simulation approximates the expected value.
Use the law of large numbers to conclude that the average of the simulation approximates the expected value.
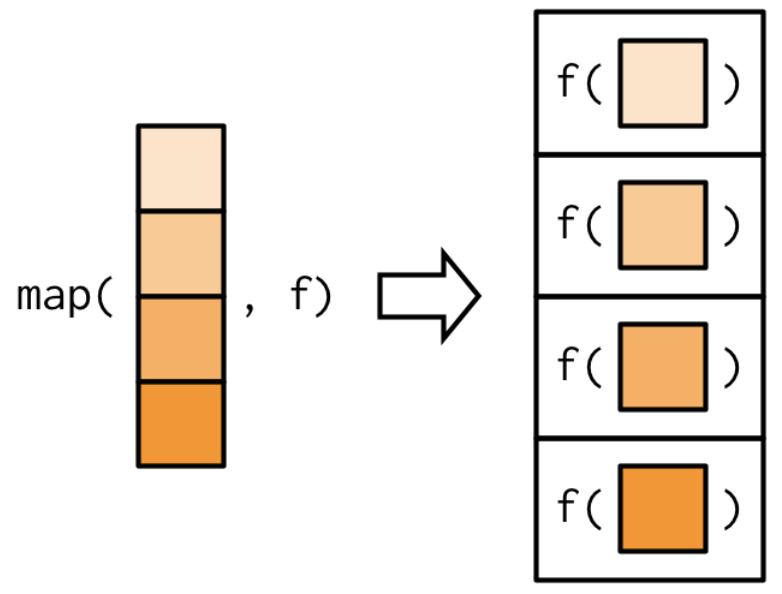
Using functional programming and the map() function
Functional programming is typically much faster than for loops are, and they also fit more cleanly into a tidy pipeline. The map functions (in the purrr package) are named by the output the produce. Some of the map() functions include:
map(.x, .f) is the main mapping function and returns a list
map_df(.x, .f) returns a data frame
map_dbl(.x, .f) returns a numeric (double) vector
map_chr(.x, .f) returns a character vector
map_lgl(.x, .f) returns a logical vector
From Advanced R by Wickham. https://adv-r.hadley.nz/functionals.html
Note that the first argument is always the data object and the second object is always the function you want to iteratively apply to each element in the input object.
To use functional programming on expected value problem, the first step is to write a function (here called sum_unif()) which will select uniform random variables until they add up to more than one. Note that the function itself doesn’t have any arguments.
Using map(), the sum_unif() function is run reps number of times. Note that sum_unif() doesn’t have any arguments, so it doesn’t really matter what the form of the input is for sum_unif().
The word “simulate” can mean a variety of things. In this course, we will simulate under various settings: sampling, shuffling, and resampling. All of the simultion methods can be done using the same R function sample()
alph<-letters[1:10]alph
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j"
sample(alph, 5, replace =FALSE)# sample (from a population)
[1] "g" "i" "h" "b" "a"
sample(alph, 15, replace =TRUE)# sample (from a population)
[1] "i" "e" "d" "i" "d" "a" "c" "h" "a" "a" "b" "f" "i" "e" "h"
Three simulating methods are used for different purposes:
Monte Carlo methods - use sampling repeated sampling from populations with known (either via data or via populations) characteristics. [Note, another very common tool for sampling from a population is to use a probability model. Some of the distribution functions we will use include rnorm(), runif(), rbinom(), etc.]
Randomization / Permutation methods - use shuffling (sampling without replacement) to test hypotheses of “no effect”.
Bootstrap methods - use resampling (sampling with replacement) to establish confidence intervals.
4.2 Understanding complicated models
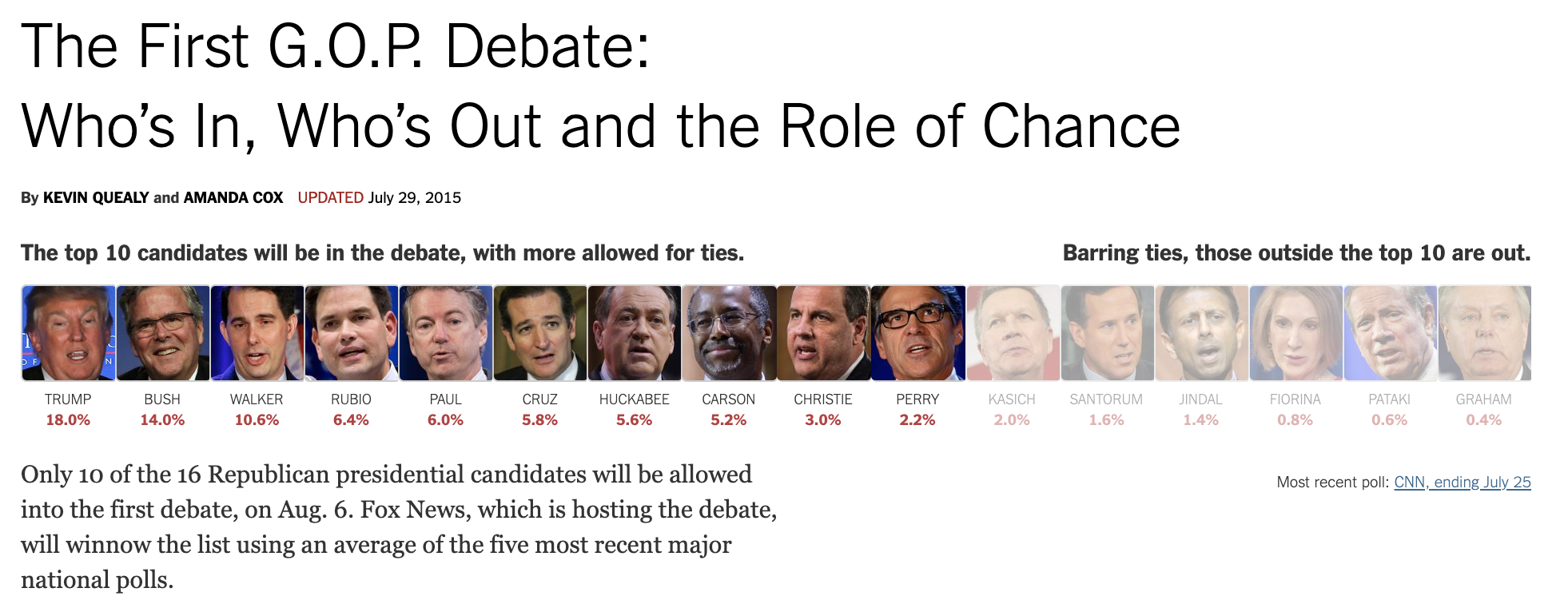
Consider the following simulation where the top 10 GOP candidates get to participate in the debate, and the remaining 6 are kept out (example taken for debate on August 6, 2015). The write-up (and example) is a few years old, but the process is identical to the process used for deciding who is eligible for the 2020 Democratic debates for president. http://www.nytimes.com/interactive/2015/07/21/upshot/election-2015-the-first-gop-debate-and-the-role-of-chance.html?_r=0
A candidate needed to get at least two percent support in four different polls published from a list of approved pollsters between June 28 and August 28, 2019, which cannot be based on open-ended questions and may cover either the national level or one of the first four primary/caucus states (Iowa, New Hampshire, Nevada, and South Carolina). Only one poll from each approved pollster counted towards meeting the criterion in each region. Wikipedia
For the 2016 election the Republican primary debates allowed only the top 10 candidates, ranked by national polls NYT
4.2.1 Goals of simulating complicated models
The goal of simulating a complicated model is not only to create a program which will provide the desired results. We also hope to be able to code such that:
The problem is broken down into small pieces
The problem has checks in it to see what works (run the lines inside the if statements!)
Simple code is best
4.2.2 Simulating to assess bias - variance trade-off
We will see the bias-variance trade-off repeatedly, particularly when we get to learning about some of the machine learning methods. But we can start to understand the bias-variance trade-off using simulated bivariate datasets.
4.2.2.1 What is variance? What is bias?
Variance refers to the amount by which \(\hat{f}\) would change if we estimated it using a different training set. Generally, the closer the model fits the data, the more variable it will be (it’ll be different for each data set!). A model with many many explanatory variables will often fit the data too closely.
Bias refers to the error that is introduced by approximating the “truth” by a model which is too simple. For example, we often use linear models to describe complex relationships, but it is unlikely that any real life situation actually has a true linear model. However, if the true relationship is close to linear, then the linear model will have a low bias.
Generally, the simpler the model, the lower the variance. The more complicated the model, the lower the bias.
4.2.2.2 Mathematically
We can measure how well a model does by looking at how close the fit of the model (\(\hat{f}\)) is to the observed data (\(y\)). We used expected (think “average” or “mean”) squared error: mean squared error (MSE).
# A tibble: 567 × 6
# Groups: dataset [9]
ex eps why dataset fit prediction
<dbl> <dbl> <dbl> <int> <fct> <dbl>
1 0 9.97 9.97 1 underfit -14.8
2 0 9.97 9.97 1 good fit 3.93
3 0 9.97 9.97 1 overfit 9.92
4 0.5 3.56 3.81 1 underfit -9.99
5 0.5 3.56 3.81 1 good fit 3.12
6 0.5 3.56 3.81 1 overfit 4.06
7 1 0.927 1.93 1 underfit -5.18
8 1 0.927 1.93 1 good fit 2.90
9 1 0.927 1.93 1 overfit 1.52
10 1.5 -1.41 0.841 1 underfit -0.370
# ℹ 557 more rows
Model 1: y ~ x
datasets|>filter(fit=="underfit")|>ggplot(aes(x =ex, y =why))+geom_point(size =0.25)+geom_line(aes(y =prediction))+facet_wrap(~dataset)
Model 2: y ~ x + x^2
datasets|>filter(fit=="good fit")|>ggplot(aes(x =ex, y =why))+geom_point(size =0.25)+geom_line(aes(y =prediction))+facet_wrap(~dataset)
Model 3: y ~ x + x^2 + x^3 + x^4 + x^5 + x^6 + x^7 + x^8 + x^9 + x^10
datasets|>filter(fit=="overfit")|>ggplot(aes(x =ex, y =why))+geom_point(size =0.25)+geom_line(aes(y =prediction))+facet_wrap(~dataset)
4.2.2.5 What we know about bias-variance trade-off
The underfit model looks the same for every dataset! That is, the model has low variance.
The underfit model doesn’t fit the data very well. The model has high bias.
The overfit model is very flexible, and looks like it fits the model very well. It has low bias.
The fitted models look quite different across the different datasets. The overfit model has high variance.
4.2.3 Simulating to assess sensitivity
As a second use of simulations, we can assess the sensitivity of parameters, model assumptions, sample size, etc. Ideally, the results will be summarized graphically, instead of as a table. A graphical representation can often provide insight into how parameters are related, whereas a table can be very hard to read.
Bias in the data is certainly a problem, especially when labels are gathered by human beings. But its far from being the only problem. In this post, I want to walk through a very simple example in which the algorithm designer is being entirely reasonable, there are no human beings injecting bias into the labels, and yet the resulting outcome is “unfair”. Here is the (toy) scenario – the specifics aren’t important. High school students are applying to college, and each student has some innate “talent” \(I\), which we will imagine is normally distributed, with mean 100 and standard deviation 15: \(I \sim N(100,15)\). The college would like to admit students who are sufficiently talented — say one standard deviation above the mean (so, it would like to admit students with \(I \geq 115\)). The problem is that talent isn’t directly observable. Instead, the college can observe grades \(g\) and SAT scores \(s\), which are a noisy estimate of talent. For simplicity, lets imagine that both grades and SAT scores are independently and normally distributed, centered at a student’s talent level, and also with standard deviation 15: \(g \sim N(I, 15)\), \(s \sim N(I, 15)\).
In this scenario, the college has a simple, optimal decision rule: It should run a linear regression to try and predict student talent from grades and SAT scores, and then it should admit the students whose predicted talent is at least 115. This is indeed “driven by math” – since we assumed everything was normally distributed here, this turns out to correspond to the Bayesian optimal decision rule for the college.
The data
Ok. Now lets suppose there are two populations of students, which we will call Reds and Blues. Reds are the majority population, and Blues are a small minority population – the Blues only make up about 1% of the student body. But the Reds and the Blues are no different when it comes to talent: they both have the same talent distribution, as described above. And there is no bias baked into the grading or the exams: both the Reds and the Blues also have exactly the same grade and exam score distributions, as described above.
But there is one difference: the Blues have a bit more money than the Reds, so they each take the SAT twice, and report only the highest of the two scores to the college. This results in a small but noticeable bump in their average SAT scores, compared to the Reds.
Two separate models
So what is the effect of this when we use our reasonable inference procedure? First, lets consider what happens when we learn two different regression models: one for the Blues, and a different one for the Reds. We don’t see much difference:
# A tibble: 2 × 6
color tpr fpr fnr fdr error
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 blue 0.490 0.0341 0.510 0.284 0.105
2 red 0.502 0.0385 0.498 0.290 0.111
The Red classifier makes errors approximately 11.108% of the time. The Blue classifier does about the same — it makes errors about 10.5% of the time. This makes sense: the Blues artificially inflated their SAT score distribution without increasing their talent, and the classifier picked up on this and corrected for it. In fact, it is even a little more accurate!
And since we are interested in fairness, lets think about the false negative rate of our classifiers. “False Negatives” in this setting are the people who are qualified to attend the college (\(I > 115\)), but whom the college mistakenly rejects. These are really the people who have come to harm as a result of the classifier’s mistakes. And the False Negative Rate is the probability that a randomly selected qualified person is mistakenly rejected from college — i.e. the probability that a randomly selected student is harmed by the classifier. We should want that the false negative rates are approximately equal across the two populations: this would mean that the burden of harm caused by the classifier’s mistakes is not disproportionately borne by one population over the other. This is one reason why the difference between false negative rates across different populations has become a standard fairness metric in algorithmic fairness — sometimes referred to as “equal opportunity.”
So how do we fare on this metric? Not so badly! The Blue model has a false negative rate of 51.007% on the blues, and the Red model has a false negative rate of 49.802% on the reds — so the difference between these two is a satisfyingly small -1.205%.
One global model
But you might reasonably object: because we have learned separate models for the Blues and the Reds, we are explicitly making admissions decisions as a function of a student’s color! This might sound like a form of discrimination, baked in by the algorithm designer — and if the two populations represent e.g. racial groups, then its explicitly illegal in a number of settings, including lending.
# A tibble: 2 × 6
color tpr fpr fnr fdr error
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 blue 0.611 0.0541 0.389 0.336 0.104
2 red 0.501 0.0381 0.499 0.288 0.111
So what happens if we don’t allow our classifier to see group membership, and just train one classifier on the whole student body? The gap in false negative rates between the two populations balloons to 11.004%. Additionally, the Blues now have a higher false positive rate (people who don’t have talent about 115 are let in accidentally) and the Reds now have a higher false negative rate (people who do have talent are mistakenly kept out). This means if you are a qualified member of the Red population, you are substantially more likely to be mistakenly rejected by our classifier than if you are a qualified member of the Blue population.
What happened????
What happened? There wasn’t any malice anywhere in this data pipeline. Its just that the Red population was much larger than the Blue population, so when we trained a classifier to minimize its average error over the entire student body, it naturally fit the Red population – which contributed much more to the average. But this means that the classifier was no longer compensating for the artificially inflated SAT scores of the Blues, and so was making a disproportionate number of errors on them – all in their favor.
This is the kind of thing that happens all the time: whenever there are two populations that have different feature distributions, learning a single classifier (that is prohibited from discriminating based on population) will fit the bigger of the two populations, simply because they contribute more to average error. Depending on the nature of the distribution difference, this can be either to the benefit or the detriment of the minority population. And not only does this not involve any explicit human bias, either on the part of the algorithm designer or the data gathering process, it is exacerbated if we artificially force the algorithm to be group blind. Well intentioned “fairness” regulations prohibiting decision makers form taking sensitive attributes into account can actually make things less fair and less accurate at the same time.
4.3 Assessing sensitivity of inferential procedures
4.3.1 Technical Conditions
Definitions
p-value is the probability of obtaining the observed data or more extreme given the null hypothesis is true.
\((1-\alpha)100\)% confidence interval is a range of values collected in such a way that repeated samples of data (using the same mechanism) would capture the parameter of interest in \((1-\alpha)100\)% of the intervals.
Examples
Equal variance in the t-test Recall that one of the technical conditions for the t-test is that the two samples come from populations where the variance is equal (at least when var.equal=TRUE is specified). What happens if the null hypothesis is true (i.e., the means are equal!) but the technical conditions are violated (i.e., the variances are unequal)?
t-test function (for use in map())
t_test_pval<-function(df){t.test(y~x1, data =df, var.equal =TRUE)|>tidy()|>select(estimate, p.value)}
generating data (equal variance)
set.seed(470)reps<-1000n_obs<-20null_data_equal<-data.frame(row_id =seq(1, n_obs, 1))|>slice(rep(row_id, each =reps))|>mutate( sim_id =rep(1:reps, n_obs), x1 =rep(c("group1", "group2"), each =n()/2), y =rnorm(n(), mean =10, sd =rep(c(1,1), each =n()/2)))|>arrange(sim_id, row_id)|>group_by(sim_id)|>nest()
summarize p-values
(Note: we rejected 4.5% of the null tests, close to 5%.)
set.seed(470)reps<-1000n_obs<-20null_data_unequal<-data.frame(row_id =seq(1, n_obs, 1))|>slice(rep(row_id, each =reps))|>mutate( sim_id =rep(1:reps, n_obs), x1 =rep(c("group1", "group2"), each =n()/2), y =rnorm(n(), mean =10, sd =rep(c(1,100), each =n()/2)))|>arrange(sim_id, row_id)|>group_by(sim_id)|>nest()
summarize p-values
(Note, we rejected 5.7% of the null tests, not too bad!)
The ISCAM applet by Beth Chance and Allan Rossman (Chance and Rossman 2018) demonstrates ideas of confidence intervals and what the analyst should expect with inferential assessment.
Consider the following linear model with the points normally distributed with equal variance around the line. [Spoiler: when the technical conditions are met, the theory works out well. It turns out that the confidence interval will capture the true parameter in 95% of samples!]
beta_coef<-function(df){lm(y~x1+x2, data =df)|>tidy(conf.int =TRUE)|>filter(term=="x2")|>select(estimate, conf.low, conf.high, p.value)}
DATA
eqvar_data<-data.frame(row_id =seq(1, n_obs, 1))|>slice(rep(row_id, each =reps))|>mutate( sim_id =rep(1:reps, n_obs), x1 =rep(c(0,1), each =n()/2), x2 =runif(n(), min =-1, max =1), y =beta0+beta1*x1+beta2*x2+rnorm(n(), mean =0, sd =1))|>arrange(sim_id, row_id)|>group_by(sim_id)|>nest()eqvar_data
We captured the true slope parameter in 95.5% of the confidence intervals (i.e., 95.5% of the datasets created confidence intervals that captured the true parameter).
Consider the following linear model with the points normally distributed with unequal variance around the line. [Spoiler: when the technical conditions are met, the theory does not work out as well. It turns out that the confidence interval will not capture the true parameter in 95% of samples!]
beta_coef<-function(df){lm(y~x1+x2, data =df)|>tidy(conf.int =TRUE)|>filter(term=="x2")|>select(estimate, conf.low, conf.high, p.value)}
DATA
uneqvar_data<-data.frame(row_id =seq(1, n_obs, 1))|>slice(rep(row_id, each =reps))|>mutate( sim_id =rep(1:reps, n_obs), x1 =rep(c(0,1), each =n()/2), x2 =runif(n(), min =-1, max =1), y =beta0+beta1*x1+beta2*x2+rnorm(n(), mean =0, sd =1+x1+10*abs(x2)))|>arrange(sim_id, row_id)|>group_by(sim_id)|>nest()uneqvar_data
You can familiarize yourself with how to play Pass the Pigs at http://www.hasbro.com/common/instruct/passthepigs.pdf and https://en.wikipedia.org/wiki/Pass_the_Pigs.
For more information on how to play Pass the Pigs, google online resources and see the following manuscript, http://pubsonline.informs.org/doi/pdf/10.1287/ited.1120.0088 Analytics, Pedagogy and the Pass the Pigs Game, (2012), Gorman, INFORMS Transactions on Education 1.
More sophisticated modeling: http://www.amstat.org/publications/jse/v14n3/datasets.kern.html
Some strategies for playing: http://passpigs.tripod.com/strat.html (The link has other stuff, too.)
4.4.1.2 Blackjack
Example and code come from Data Science in R: a case studies approach to computational reasoning and problem solving, by Nolan and Temple Lang, Chapter 9 Simulating Blackjack, by Hadley Wickham
More about the game of blackjack, there are many online resources that you can use to learn about the came. Two resources that Nolan and Temple Lang recommend are http://wizardofodds.com/games/blackjack/ and http://hitorstand.net/.
Basic Blackjack
Card game, goal: sum cards as close to 21 without going over
A few nuances to card value (e.g., Ace can be 1 or 11)
Start with 2 cards, build up one card at a time
Lots of different strategies (also based on dealer’s cards)
What do we need to simulate poker?
set-up of cards, dealing, hands
“score” (both sum of cards and payout)
strategies
result of strategies (summary of outcomes)
Source
Example and code come from Data Science in R: a case studies approach to computational reasoning and problem solving by Nolan and Temple Lang.
handValue=function(cards){value=sum(cards)# Check for an Ace and change value if it doesn't bustif(any(cards==1)&&value<=11)value=value+10value# Check bust (set to 0); check Blackjack (set to 21.5)if(value>21)0elseif(value==21&&length(cards)==2)21.5# Blackjackelsevalue}handValue(c(10,4))
check=testWinnings# make the matrix the right sizecheck[]=NA# make all entries NAfor(iinseq_along(test_vals)){for(jinseq_along(test_vals)){check[i, j]=winnings(test_vals[i], test_vals[j])}}identical(check, testWinnings)
[1] TRUE
Function for getting more cards
shoe=function(m=1)sample(deck, m, replace =TRUE)new_hand=function(shoe, cards=shoe(2), bet=1){list(bet =bet, shoe =shoe, cards =cards)}myCards=new_hand(shoe, bet =7)myCards
$bet
[1] 7
$shoe
function (m = 1)
sample(deck, m, replace = TRUE)
$cards
[1] 10 1
play_hand=function(shoe, strategy, hand=new_hand(shoe), dealer=dealer_cards(shoe)){face_up_card=dealer[1]action=strategy(hand$cards, face_up_card)while(action!="S"&&handValue(hand$cards)!=0){if(action=="H"){hand=hit(hand)action=strategy(hand$cards, face_up_card)}else{stop("Unknown action: should be one of S, H")}}winnings(handValue(dealer), handValue(hand$cards))*hand$bet}
Step 1: Need a Roulette wheel! … and money
Step 2: Will spin the wheel
Step 3: Depending on the wheel, update the money.
* if spin is red: money + 1
* if spin is not red: money - 1
Step 4: Keep spinning until money = 40 or money = 0
Step 5: Repeat many times
Note that map() is specifically designed to work in vectorized ways, so it doesn’t have an easy while() companion. Which means that we need to make sure to iterate long enough to either lose or double our money.
output<-1:20|>map(game_func, money =20, iter =100000)|>list_rbind()output|>head()
set.seed(4747)money<-10games<-20iterations<-100001:games|>map(game_func, money =money, iter =iterations)|>list_rbind()|>group_by(rep)|>filter(interim_money>=2*money|interim_money<=0)|>group_by(rep)|>slice_min(game)|>ungroup()|>summarize(prop_double =mean(interim_money==2*money))
# A tibble: 1 × 1
prop_double
<dbl>
1 0.25
4.5 Generating random numbers
You are not responsible for the material on generating random numbers, but it’s pretty cool stuff that relies heavily on simulation.
4.5.1 How do we generate uniform[0,1] numbers?
LCG - linear congruence generators. Set \(a,b,m\) to be large integers. The sequence of numbers \(X_i / m\) will pass all tests for uniformly distributed variables. \[ X_{n+1} = (aX_n + b) \mod m \]
where
\(m\) and \(b\) are relatively prime,
\(a - 1\) is divisible by all prime factors of \(m\),
\(a - 1\) is divisible by 4 if \(m\) is divisible by 4.
4.5.2 Generating other RVs: The Inverse Transform Method
You are not responsible for the material on generating random numbers, but it’s pretty cool stuff that relies heavily on simulation.
Continuous RVs
Use the inverse of the cumulative distribution function to generate data that come from a particular continuous distribution. For example, generate 100 random normal deviates. Start by assuming that \(F\) is a continuous and increasing function. Also assume that \(F^{-1}\) exists.
\[F(x) = P(X \leq x)\] Note that \(F\) is just the area function describing the density (histogram) of the data.
Algorithm: Generate Continuous RV
Generate a uniform random variable \(U\)
Set \(X = F^{-1}(U)\)
Proof: that the algorithm above generates variables that come from the probability distribution represented by \(F\).
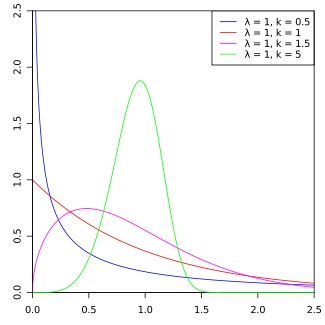
Suppose you could simulate uniform random variables, \(U_1, U_2, \dots\). How could you use these to simulate RV’s with the Weibull density, \(f(x)\), given above? \[ \mbox{Let: } X_i = \sqrt{-\ln(1-U_i)}\]
A similar algorithm is used to generate data that come from a particular discrete distribution. For example, generate 100 random normal deviates. We start by assuming the probability mass function of \(X\) is \[ P(X = x_i) = p_i, i=1, \ldots, m\]
Algorithm: Generate Discrete RV
Generate a uniform random variable \(U\)
Transform \(U\) into \(X\) as follows, \[X = x_j \mbox{ if } \sum_{i=1}^{j-1} p_i \leq U \leq \sum_{i=1}^j p_i\]
Proof: that the algorithm above generates variables that come from the probability mass function \(\{p_1, p_2, \ldots, p_m\}\).
What if you don’t know \(F\)? Or can’t calculate \(F^{-1}\)?
In the case that the CDF cannot be calculated explicitly (the normal for example), one could still use this methodology by estimating F at a collection of points \(x_i, u_i = F(x_i)\). Now we temporarily mimic the discrete inverse transform, as we generate a \(U\) and see which subinterval it falls in, i.e. \(u_i \leq U \leq u_{i+1}\). Assuming the \(x_i\) are close enough, we expect the CDF to be approximately linear on this subinterval, so then we take a linear interpolation of the CDF on the subinterval to get \(X\) via
However, the linear interpolation requires a complete approximation of \(F(x)\), regardless of the sample size desired, and doesn’t generalize to higher dimensions, and of course only gives you something with the approximate distribution back, even if you have your hands on real uniform random variables.
4.6 References
Chance, Beth, and Allan Rossman. 2018. Investigating Statistics, Concepts, Applications, and Methods. 3rd ed. http://www.rossmanchance.com/iscam3/.
The expected value here is over the model \(\hat{f}(x)\), not over the random variable \(X\). That is, \(\epsilon\) is the thing that varies.↩︎