5 Permutation Tests
Motivation:
- Great video of how/why computational statistical methods can be extremely useful. And it’s about beer and mosquitoes! John Rauser from Pintrest gives the keynote address at Strata + Hadoop World Conference October 16, 2014. David Smith, Revolution Analytics blog, October 17, 2014. http://blog.revolutionanalytics.com/2014/10/statistics-doesnt-have-to-be-that-hard.html
- A more complicated scenario with the same tools being applied. Here the point is to understand gerrymandering. https://www.youtube.com/watch?v=gRCZR_BbjTo&t=125s
The big lesson here, IMO, is that so many statistical problems can seem complex, but you can actually get a lot of insight by recognizing that your data is just one possible instance of a random process. If you have a hypothesis for what that process is, you can simulate it, and get an intuitive sense of how surprising your data is. R has excellent tools for simulating data, and a couple of hours spent writing code to simulate data can often give insights that will be valuable for the formal data analysis to come. (David Smith)
Rauser says that the in order to follow a statistical argument that uses simulation, you need three things:
- Ability to follow a simple logical argument.
- Random number generation.
- Iteration
5.1 Inference Algorithms
5.1.1 Hypothesis Test Algorithm
Before working out the nitty gritty details, recall the structure of hypothesis testing. Consider the applet on Simulating ANOVA Tables (Chance & Rossman) http://www.rossmanchance.com/applets/AnovaSim.html
- Choose a statistic that measures the effect you are looking for. For example, the ANOVA F statistic is:
\[\begin{align} F &= \frac{\text{between-group variability}}{\text{within-group variability}}\\ &= \frac{\sum_i n_i(\overline{X}_{i\cdot} - \overline{X})^2/(K-1)}{\sum_{ij} (X_{ij}-\overline{X}_{i\cdot})^2/(N-K)} \end{align}\]
Construct the sampling distribution that this statistic would have if the effect were not present in the population (the null sampling distribution). [The sampling distributions for t statistics and F statistics are based on the Central Limit Theorem and derived in Math 152.]
Locate the observed statistic in the null distribution. A value in the main body of the distribution could easily occur just by chance. A value in the tail would rarely occur by chance and so is evidence that something other than chance is operating. [This piece is going to happen in permutation tests as well as in analytic tests – the point is to see if the observed data is consistent with the null distribution.]
p-value is the probability of the observed data or more extreme if the null hypothesis is true. [Same definition for analytic, permutation, and randomization tests!]
To estimate the p-value for a test of significance, estimate the sampling distribution of the test statistic when the null hypothesis is true by simulating in a manner that is consistent with the null hypothesis. Alternatively, there are analytic / mathematical formulas for many of the common statistical hypothesis tests.
5.1.2 Permutation Tests Algorithm
To evaluate the p-value for a permutation test, estimate the sampling distribution of the test statistic when the null hypothesis is true by resampling in a manner that is consistent with the null hypothesis (the number of resamples is finite but can be large!).
Choose a test statistic
Shuffle the data (force the null hypothesis to be true)
Create a null sampling distribution of the test statistic (under \(H_0\))
Find the observed test statistic on the null sampling distribution and compute the p-value (observed data or more extreme). The p-value can be one or two-sided.
Technical Conditions
Permutation tests fall into a broad class of tests called “non-parametric” tests. The label indicates that there are no distributional conditions required about the data (i.e., no condition that the data come from a normal or binomial distribution). However, a test which is “non-parametric” does not meant that there are no conditions on the data, simply that there are no distributional or parametric conditions on the data. The parameters are at the heart of almost all parametric tests.
For permutation tests, we are not basing the test on population parameters, so we don’t need to make any claims about them (i.e., that they are the mean of a particular distribution).
-
Permutation The different treatments have the same effect. [Note: exchangeability, same population, etc.] If the null hypothesis is true, the labels assigning groups are interchangeable with respect to the probability distribution.
- Note that it is our choice of statistic which makes the test more sensitive to some kinds of difference (e.g., difference in mean) than other kinds (e.g., difference in variance).
- Parametric For example, the different populations have the same mean.
IMPORTANT KEY IDEA the point of technical conditions for parametric or permutation tests is to create a sampling distribution that accurately reflects the null sampling distribution for the statistic of interest (the statistic which captures the relevant research question information).
5.2 Permutation tests in practice
How is the test interpreted given the different types of sampling which are possibly used to collect the data?
Random Sample The concept of a p-value usually comes from the idea of taking a sample from a population and comparing it to a sampling distribution (from many many random samples).
-
Random Experiment In the context of a randomized experiment, the p-value represents the observed data compared to “happening by chance.”
- The interpretation is direct: if there is only a very small chance that the observed statistic would take such an extreme value, as a result only of the randomization of cases: we reject the null treatment effect hypothesis. CAUSAL!
-
Observational Study In the context of observational studies the results are less strong, but it is reasonable to conclude that the effect observed in the sample reflects an effect present in the population.
- In a sample, consider the difference (or ratio) and ask “Is this difference so large it would rarely occur by chance in a particular sample constructed under the null setting?”
- If the data come from a random sample, then the sample (or results from the sample) are probably consistent with the population [i.e., we can infer the results back to the larger population].
5.2.0.1 Other Test Statistics
The example in class used a modification of the ANOVA F-statistic to compare the observed data with the permuted data test statistics. Depending on the data and question, the permuted test statistic can take on any of a variety of forms.
| Data | Hypothesis Question | Statistic |
|---|---|---|
| 2 categorical | diff in prop | \(\hat{p}_1 - \hat{p}_2\) or \(\chi^2\) |
| variables | ratio of prop | \(\hat{p}_1 / \hat{p}_2\) |
| 1 numeric | diff in means | \(\overline{X}_1 - \overline{X}_2\) |
| 1 binary | ratio of means | \(\overline{X}_1 / \overline{X}_2\) |
| diff in medians | \(\mbox{median}_1 - \mbox{median}_2\) | |
| ratio of medians | \(\mbox{median}_1 / \mbox{median}_2\) | |
| diff in SD | \(s_1 - s_2\) | |
| diff in var | \(s^2_1 - s^2_2\) | |
| ratio of SD or VAR | \(s_1 / s_2\) | |
| 1 numeric | diff in means | \(\sum n_i (\overline{X}_i - \overline{X})^2\) or |
| k groups | F stat | |
| paired or | (permute within row) | \(\overline{X}_1 - \overline{X}_2\) |
| repeated measures | ||
| regression | correlation | least sq slope |
| time series | no serial corr | lag 1 autocross |
Depending on the data, hypotheses, and original data collection structure (e.g., random sampling vs random allocation), the choice of statistic for the permutation test will vary.
5.2.1 Permutation vs. Randomization Tests
We will call randomization tests those that enumerate all possible data permutations. permutation tests, on the other hand, will permute the data \(B\) (\(< <\) all) times. [Some authors call a permutation test applied to a randomized experiment a randomization test, but we will use the term randomization to indicate that all possible permutations have been considered.]
- Main difference: randomization tests consider every possible permutation of the labels, permutation tests take a random sample of permutations of the labels.
- Both can only be applied to a comparison situation (e.g., no one sample t-tests).
- Both permute labels under \(H_0\), for example, \(H_0: F(x) = G(x)\).
- Both can be used in situations where sampling distributions are unknown (e.g., differences in medians).
- Both can be used in situations where sampling distributions are based on population distributions (e.g., ratio of variances).
- Randomization tests were the first nonparametric tests conceived (R.A. Fisher, 1935).
Randomization p-value
Let \(t^*\) be the observed test statistic. For a two sample test with \(N\) total observations and \(n\) observations in group 1, there are \({N \choose n}\) randomizations, all of which are equally likely under \(H_0\). The p-value then becomes: \[\begin{align} p_R &= P(T \leq t^* | H_0) = \frac{\sum_{i=1}^{{N \choose n}} I(t_i \leq t*)}{{N \choose n}} \end{align}\] If we choose a significance level of \(\alpha = k/{N \choose n}\), then the type I error rate is: \[\begin{align} P(\text{type I error}) &= P(p_R \leq \alpha | H_0)\\ &= P\bigg(\sum_{i=1}^{{N \choose n}} I(t_i \leq t*) \leq k | H_0 \bigg)\\ &= \frac{k}{{N \choose n}}= \alpha\\ \text{alternatively } k&= \alpha {N \choose n} \end{align}\] The point of which is to say that the randomization test controls the probability of a Type I error under the very minimal conditions that the subjects are randomized to treatments (a minimal condition, but hard to do in practice!!)
Permutation p-value
Now consider a permutation test that randomly permutes the data \(B\) times (instead of all \({N \choose n}\) times). A permutation test approximates a randomization test. In fact, the permutation test can be analyzed using the following binomial random variable: \[\begin{align} X_P &= \# \ \mbox{permutations out of B that give a more extreme value than the observed test statistic}\\ X_P &\sim Bin(p_R, B)\\ SE(X_P) &= \sqrt{\frac{p_R (1-p_R)}{B}} \approx \sqrt{\frac{\hat{p}_P (1-\hat{p}_P)}{B}} \end{align}\]
Consider a situation where interest is in a small effect, say p-value\(\approx 0.01\). The SE should be less than 0.001. \[\begin{align} 0.001 &= \sqrt{ (0.01)\cdot(0.99) / B}\\ B &= (0.01) \cdot (0.99) / (0.001)^2\\ &= 9900 \end{align}\]
Another way to look at the same problem is to use the estimated p-value = \(\hat{p}_P = \frac{X_P}{B}\) to come up with a confidence interval for \(p_R\).
CI for \(p_R \approx \hat{p}_P \pm 1.96 \sqrt{\frac{\hat{p}_P (1-\hat{p}_P)}{B}}\)
5.2.2 CI from Permutation Tests
Use shifts or rescaling to create a CI for a parameter value using permutation tests. That is, consider a situation with data from \(X\) and \(Y\) Use one of the following transformation (depending on the study): \[\begin{align} W &= Y + a\\ \mbox{or } U &= Y / b \end{align}\] and run the permutation test of interest on \(X\) vs. \(W\) or \(X\) vs. \(U\). For a series of \(a\) or \(b\) values we can find which we don’t reject at a particular level of significance (\(\alpha\)) to create a \((1-\alpha)100\%\) confidence interval.
Usually, however, we use bootstrapping for confidence intervals and permutation tests for hypothesis testing.
5.2.3 Randomization Example
5.2.3.1 Fisher’s Exact Test – computationally efficient randomization test
- N observations are classified into a 2x2 table.
- Each observation is classified into exactly one cell.
- Row and column totals are fixed.
Given fixed row and column totals, we can easily calculate the interior distribution using the hypergeometric. Note that once a single cell is filled, all other cells are determined.
| Col 1 | Col 2 | Total | |
|---|---|---|---|
| Row 1 | X | r-X | r |
| Row 2 | c-X | N-r-c+X | N-r |
| Total | c | N-c | N |
\[\begin{align} P(X=x) &= \frac{{r \choose x}{{N-r} \choose{c-x}}}{{N \choose c}}\\ & \mbox{out of those in col 1, how many are in row 1?}\\ P(X \leq x) &= \sum_{i=0}^x \frac{{r \choose i}{{N-r} \choose {c-i}}}{{N \choose c}}\\ &= \mbox{p-value} \end{align}\]
Not common for both row and column totals to be fixed. (More likely for just column totals to be fixed, e.g., men and women.) Instead, consider all subsets of the sample space with \(N\) observations. For any particular combination of row and column totals (\(rc\)):
\[\begin{align} P(\mbox{rejecting } H_0 | rc, H_0) &\leq& \alpha\\ P(\mbox{rejecting } H_0 \ \ \forall \mbox{ subsets } | H_0) &\leq& \sum_{rc \ combos} P(\mbox{rejecting } H_0 | rc, H_0) P(rc | H_0)\\ &\leq& \alpha \end{align}\]
(Note: assume $P(rc | H_0) = 1 / # rc $ combos.) The test will be valid at any \(\alpha\) level, but it won’t be as powerful as one in which fixed columns/rows is actually meaningful.
5.2.3.2 \(r \times c\) tables
- permute data in a new way
- new test stat \[\begin{align} T = \sum_{i,j} \frac{(O_{i,j} - E_{i,j})^2}{E_{i,j}} \end{align}\]
- 2-sided p-value. what do we expect? \[\begin{align} E_{i,j} = \frac{R_i C_j}{N} \end{align}\]
5.2.3.2.1 Example: Observer
In a study published in the Journal of Personality and Social Psychology (Butler and Baumeister, 1998), researchers investigated a conjecture that having an observer with a vested interest would decrease subjects’ performance on a skill-based task. Subjects were given time to practice playing a video game that required them to navigate an obstacle course as quickly as possible. They were then told to play the game on final time with an observer present. Subjects were randomly assigned to one of two groups:
- Group A was told that the participant and the observer would each win $3 if the participant beat a certain threshold.
- Group B was told that only that the participant would win the prize if the threshold was beaten.
The goal of this data analysis is to determine whether or not there is an effect from the observer on the performance. That is, like the \(\chi^2\) test, our hypotheses are:
\(H_0:\) there is no association between the two variables \(H_a:\) there is an association between the two variables
The data from the 24 subjects is given below:
| A: shares prize | B: no sharing | Total | |
|---|---|---|---|
| Beat threshold | 3 | 8 | 11 |
| Did not beat threshold | 9 | 4 | 13 |
| Total | 12 | 12 | 24 |
- Card simulation (to demonstrate how the permutation test works)
- Permutation Test (see Chance and Rossman applet for automated permutation test, http://www.rossmanchance.com/applets/ChisqShuffle.htm?FET=1)
\[\begin{align} SE(\mbox{p-value}) = \sqrt{\frac{\hat{p}_r (1-\hat{p}_r)}{100}} = 0.02 \end{align}\]
- Randomization Test \[\begin{align} P(X \leq 3) = \sum_{i=0}^3 \frac{{11 \choose i}{12 \choose {12-i}}}{{24 \choose 12}} = 0.0436 \end{align}\]
5.3 R examples
5.3.1 Cloud Seeding (Two sample test – computationally very difficult to do a randomization test)
Cloud seeding data: seeding or not seeding was randomly allocated to 52 days when seeding was appropriate. The pilot did not know whether or not the plane was seeding. Rain is measured in acre-feet.
After running tests to compare means and variances we obtain the following p-values:
| comparison of means | comparison of variances | |||
|---|---|---|---|---|
| Permutation | t-test | Permutation | F-test | |
| Raw Data | 0.031 | 0.054 | 0.068 | 0.000067 |
| Logged Data | 0.010 | 0.014 | 0.535 | 0.897 |
5.3.1.1 R code
Before doing anything, let’s look at the data. Here, we visualize with both boxplots and histograms. Also, we visualize on the raw scale as well as the log scale. Certainly, the log10 scale indicates that a transformation makes the data more symmetric.
clouds <- read_delim("figs/cloud-seeding.txt",
"\t", escape_double = FALSE, trim_ws = TRUE)
names(clouds) <- c("unseeded", "seeded")
clouds <- tidyr::pivot_longer(clouds, cols = 1:2, names_to = "seeding", values_to = "rainfall") %>%
mutate(seeding = as.factor(seeding))
clouds %>%
ggplot(aes(x=seeding, y=rainfall)) + geom_boxplot()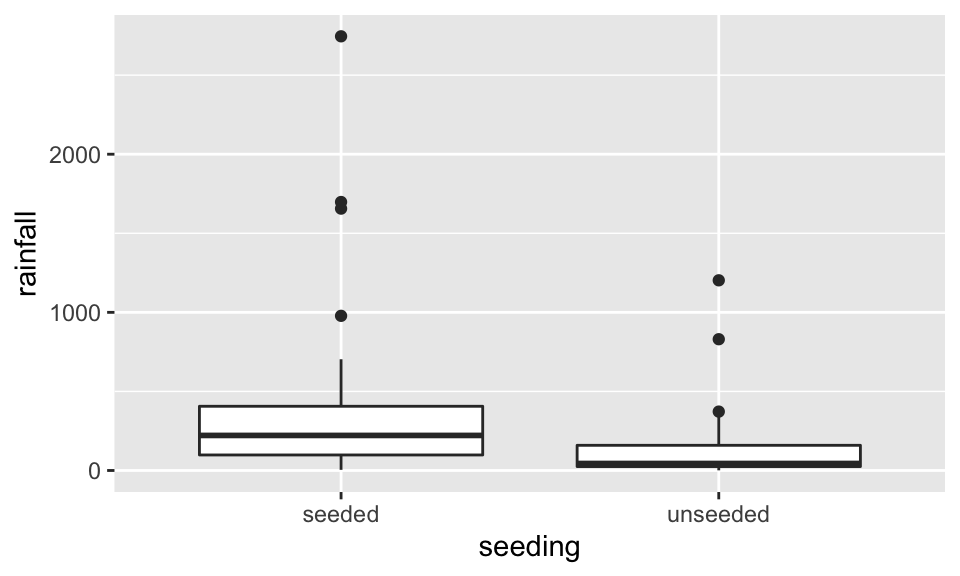
clouds %>%
ggplot(aes(x=rainfall)) + geom_histogram(bins = 20) + facet_wrap(~seeding)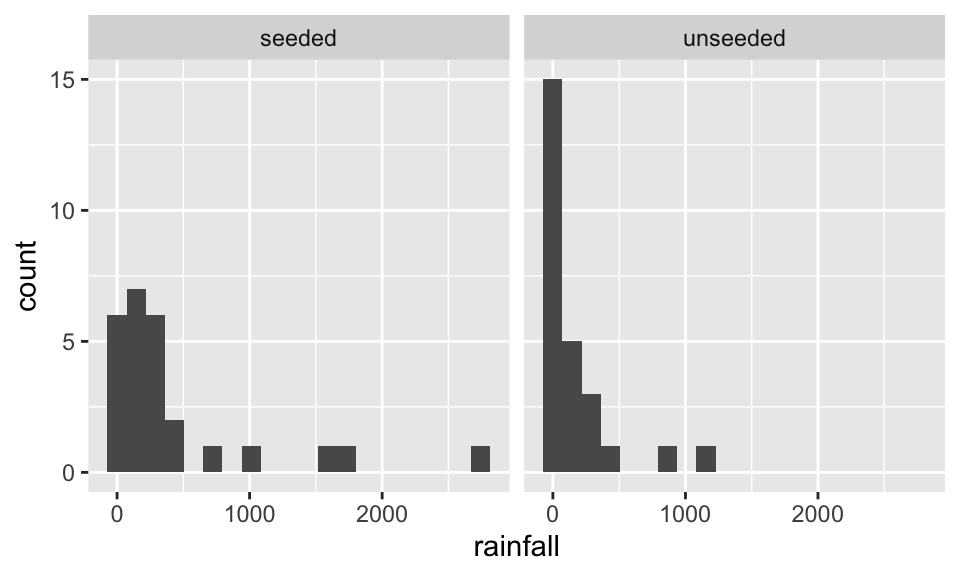
clouds %>%
ggplot(aes(x=seeding, y=rainfall)) + geom_boxplot() + scale_y_log10()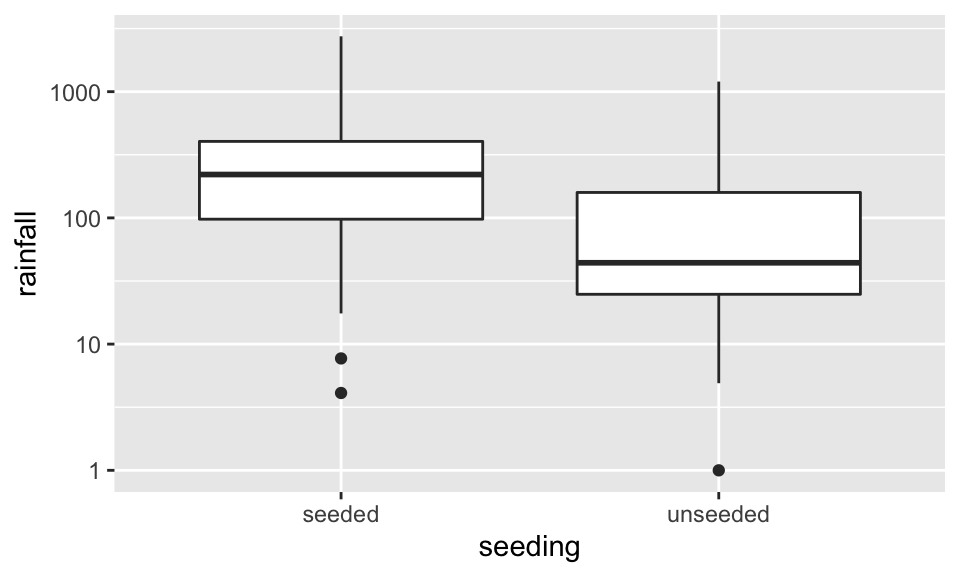
clouds %>%
ggplot(aes(x=rainfall)) + geom_histogram(bins = 20) + facet_wrap(~seeding) + scale_x_log10()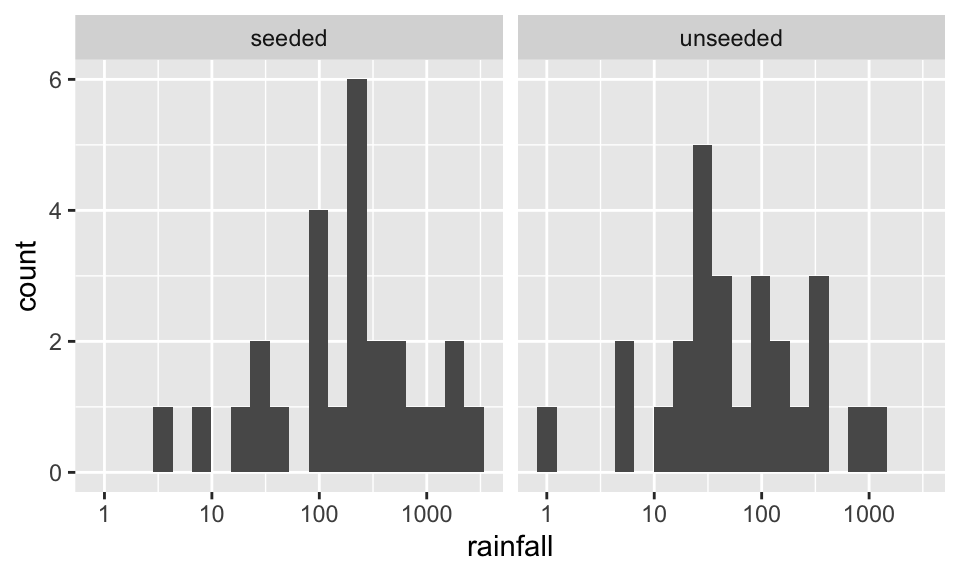
unlogged data:
clouds %>%
mutate(lnrain = log(rainfall)) %>%
group_by(seeding) %>%
summarize(meanrain = mean(rainfall), meanlnrain = mean(lnrain))## # A tibble: 2 × 3
## seeding meanrain meanlnrain
## <fct> <dbl> <dbl>
## 1 seeded 442. 5.13
## 2 unseeded 165. 3.99
clouds %>%
mutate(lnrain = log(rainfall)) %>%
group_by(seeding) %>%
summarize(meanrain = mean(rainfall), meanlnrain = mean(lnrain)) %>%
summarize(diff(meanrain), diff(meanlnrain))## # A tibble: 1 × 2
## `diff(meanrain)` `diff(meanlnrain)`
## <dbl> <dbl>
## 1 -277. -1.14
raindiffs <- clouds %>%
mutate(lnrain = log(rainfall)) %>%
group_by(seeding) %>%
summarize(meanrain = mean(rainfall), meanlnrain = mean(lnrain)) %>%
summarize(diffrain = diff(meanrain), difflnrain = diff(meanlnrain))
raindiffs## # A tibble: 1 × 2
## diffrain difflnrain
## <dbl> <dbl>
## 1 -277. -1.14Below, we’ve formally gone through a permutation. here, the resampling is not coded in a particularly tidy way, but there is a tidy way to code loops! Generally, loops are not the fasted way to code in R, so if you need to quickly run code that seems like it should go in a loop, it is very likely that purrr is the direction you want to go, https://purrr.tidyverse.org/.
5.3.1.1.1 Difference in means after permuting
reps <- 1000
permdiffs <- c()
for(i in 1:reps){
onediff <- clouds %>%
mutate(permseed = sample(seeding)) %>%
group_by(permseed) %>%
summarize(meanrain = mean(rainfall)) %>%
summarize(diff(meanrain)) %>% pull()
permdiffs <- c(permdiffs, onediff)
}
permdiffs %>% data.frame() %>%
ggplot(aes(x = permdiffs)) + geom_histogram(bins=30) + geom_vline(xintercept = raindiffs$diffrain, color = "red")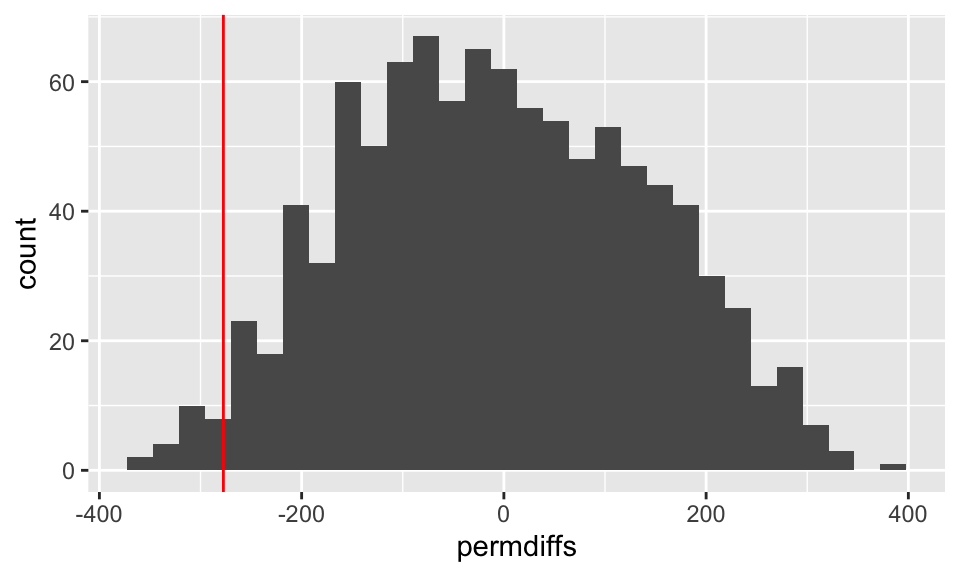
5.3.1.1.2 Ratio of variances after permuting
rainvarratio <- clouds %>%
group_by(seeding) %>%
summarize(varrain = var(rainfall)) %>%
summarize(rainratio = varrain[1] / varrain[2])
reps <- 1000
permvars <- c()
for(i in 1:reps){
oneratio <- clouds %>%
mutate(permseed = sample(seeding)) %>%
group_by(permseed) %>%
summarize(varrain = var(rainfall)) %>%
summarize(varrain[1] / varrain[2]) %>% pull()
permvars <- c(permvars, oneratio)
}
permvars %>% data.frame() %>%
ggplot(aes(x = permvars)) + geom_histogram(bins=30) + geom_vline(xintercept = rainvarratio$rainratio , color = "red")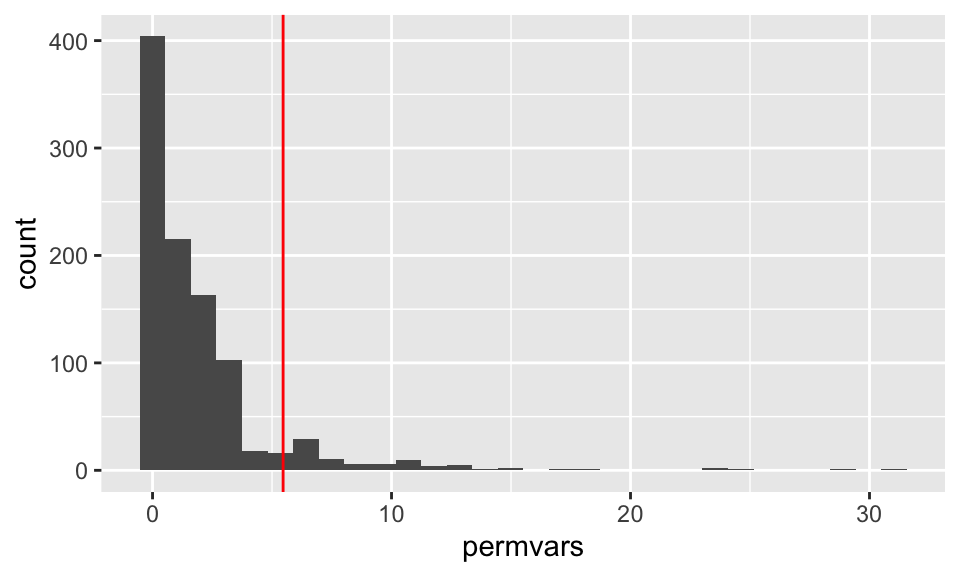
5.3.1.1.3 Testing differences in means or ratios of variances
As evidenced in the histograms above,
the permutation test (one-sided) for the difference in means will count the number of permuted differences that are less than or equal to the observed difference in means, just over 1%.
the permutation test (one-sided) for the ratio of variances will count the number of permuted ratios that are greater than or equal to the observed ratio of variances, about 7%.
(sum(raindiffs$diffrain >= permdiffs) + 1) /1000## [1] 0.024
(sum(rainvarratio$rainratio <= permvars)+1)/1000## [1] 0.0865.3.2 MacNell Teaching Evaluations (Stratified two-sample t-test)
Boring et al. (2016) reanalyze data from MacNell et al. (2014). Students were randomized to 4 online sections of a course. In two sections, the instructors swapped identities. Was the instructor who identified as female rated lower on average? (https://www.math.upenn.edu/~pemantle/active-papers/Evals/stark2016.pdf)

Figure 5.1: Kraj (2017)

Figure 5.2: Kraj (2017)

Figure 5.3: Mengel, Sauermann, and Zölitz (2019)

Figure 5.4: MacNell, Driscoll, and Hunt (2015)
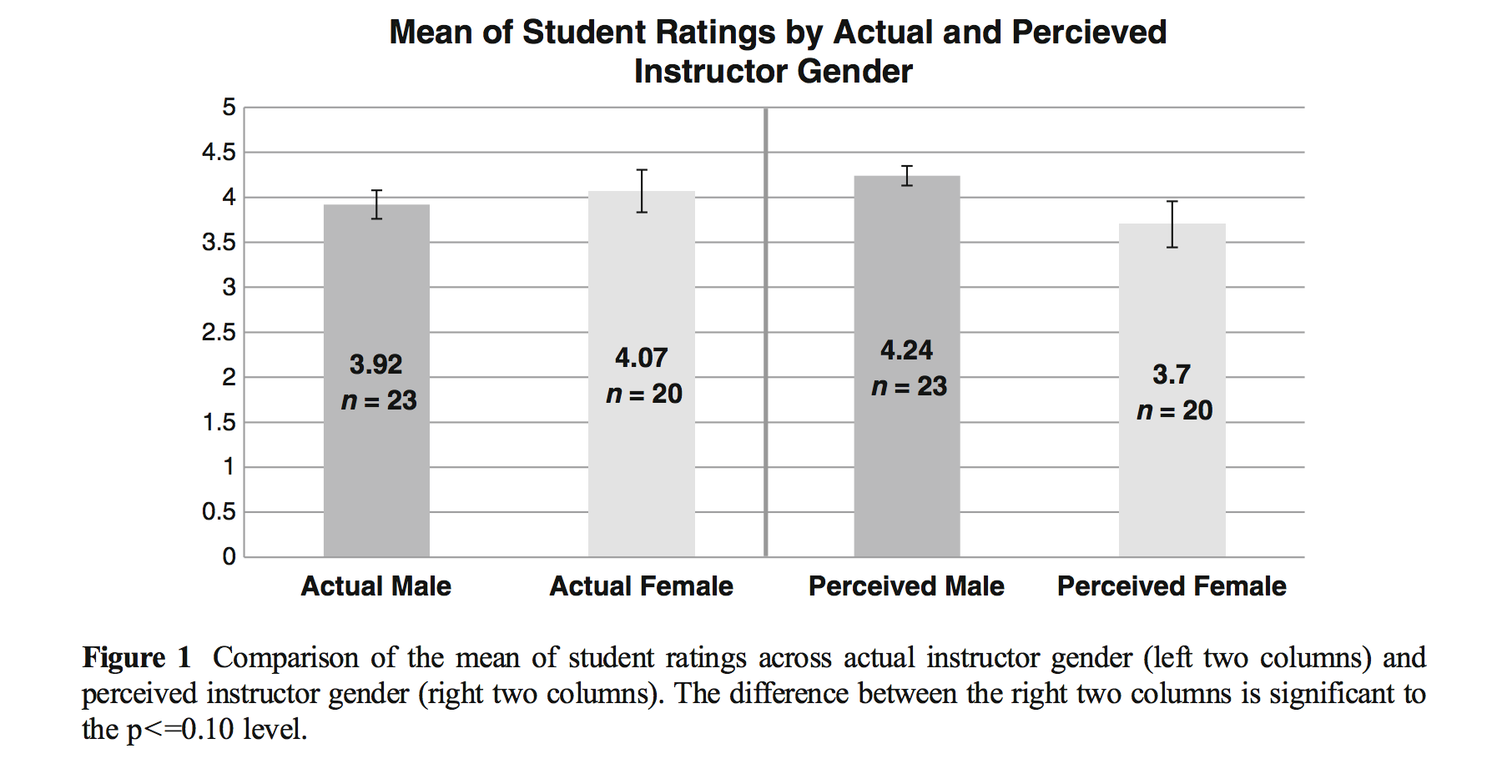
Figure 5.5: MacNell, Driscoll, and Hunt (2015)
5.3.2.0.1 R code
# The data come from `permuter` which is no longer kept up as a package
macnell <- readr::read_csv("https://raw.githubusercontent.com/statlab/permuter/master/data-raw/macnell.csv")
#library(permuter)
#data(macnell)
library(ggridges)
macnell %>%
mutate(TAID = ifelse(taidgender==1, "male", "female")) %>%
mutate(TAGend = ifelse(tagender==1, "male", "female")) %>%
ggplot(aes(y=TAGend, x=overall, group = interaction(TAGend, TAID),
fill=TAID)) +
geom_point(position=position_jitterdodge(jitter.height=0.3, jitter.width = 0, dodge.width = 0.4), aes(color = TAID)) +
stat_summary(fun="mean", geom="crossbar", size=.3, width = 1,
aes(color = TAID),
position=position_dodge(width=0.4)) +
stat_summary(fun="mean", geom="point", shape = "X",
size=5, aes(color = TAID),
position=position_dodge(width=0.4)) +
coord_flip() +
xlab("") +
ggtitle("Overall teaching effectiveness score")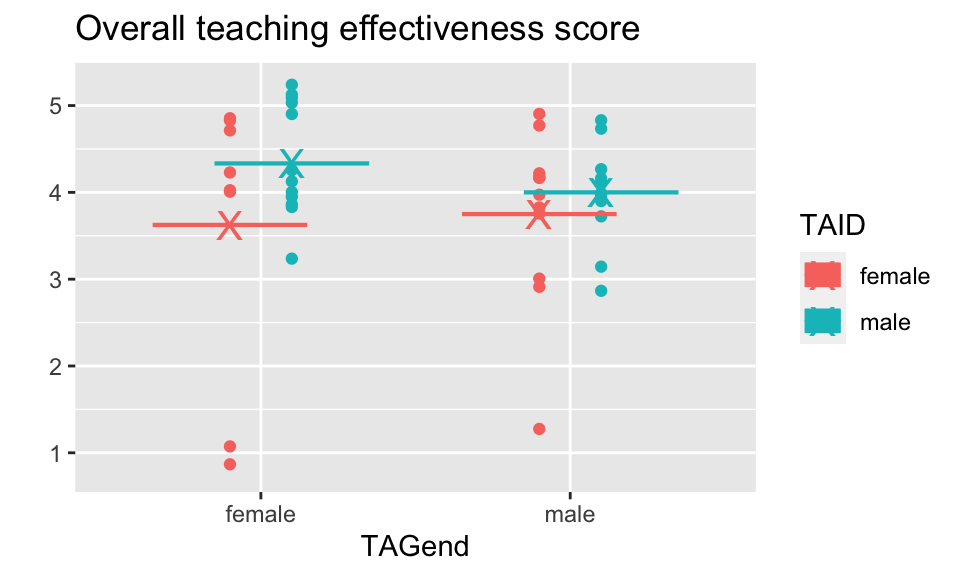
5.3.2.1 Analysis goal
Want to know if the score for the perceived gender is different.
\[H_0: \mu_{ID.Female} = \mu_{ID.Male}\] > Although for the permutation test, under the null hypothesis not only are the means of the population distributions the same, but the variance and all other aspects of the distributions across perceived gender.
5.3.2.2 MacNell Data without permutation
## # A tibble: 15 × 3
## overall tagender taidgender
## <dbl> <dbl> <dbl>
## 1 4 0 1
## 2 4 0 1
## 3 5 0 1
## 4 5 0 1
## 5 5 0 1
## 6 4 0 1
## 7 4 0 1
## 8 5 0 1
## 9 4 0 1
## 10 3 0 1
## 11 5 0 1
## 12 4 0 1
## 13 5 1 1
## 14 5 1 1
## 15 4 1 15.3.2.3 Permuting MacNell data
Conceptually, there are two levels of randomization:
\(N_m\) students are randomly assigned to the male instructor and \(N_f\) are assigned to the female instructor.
Of the \(N_j\) assigned to instructor \(j\), \(N_{jm}\) are told that the instructor is male, and \(N_{jf}\) are told that the instructor is female for \(j=m,f\).
## # A tibble: 4 × 3
## # Groups: tagender [2]
## tagender taidgender `n()`
## <dbl> <dbl> <int>
## 1 0 0 11
## 2 0 1 12
## 3 1 0 13
## 4 1 1 11Stratified two-sample test:
- For each instructor, permute perceived gender assignments.
- Use difference in mean ratings for female-identified vs male-identified instructors.
macnell %>%
group_by(tagender) %>%
mutate(permTAID = sample(taidgender, replace=FALSE)) %>%
select(overall, tagender, taidgender, permTAID) ## # A tibble: 47 × 4
## # Groups: tagender [2]
## overall tagender taidgender permTAID
## <dbl> <dbl> <dbl> <dbl>
## 1 4 0 1 0
## 2 4 0 1 0
## 3 5 0 1 0
## 4 5 0 1 0
## 5 5 0 1 0
## 6 4 0 1 1
## 7 4 0 1 0
## 8 5 0 1 0
## 9 4 0 1 1
## 10 3 0 1 1
## # … with 37 more rows
## # ℹ Use `print(n = ...)` to see more rows
macnell %>%
group_by(tagender) %>%
mutate(permTAID = sample(taidgender, replace=FALSE)) %>%
ungroup(tagender) %>%
group_by(permTAID) %>%
summarize(pmeans = mean(overall, na.rm=TRUE)) %>%
summarize(diff(pmeans))## # A tibble: 1 × 1
## `diff(pmeans)`
## <dbl>
## 1 -0.00652
diff_means_func <- function(.x){
macnell %>% group_by(tagender) %>%
mutate(permTAID = sample(taidgender, replace=FALSE)) %>%
ungroup(tagender) %>%
group_by(permTAID) %>%
summarize(pmeans = mean(overall, na.rm=TRUE)) %>%
summarize(diff_mean = diff(pmeans))
}
map_df(1:5, diff_means_func)## # A tibble: 5 × 1
## diff_mean
## <dbl>
## 1 -0.468
## 2 0.180
## 3 0.370
## 4 -0.00216
## 5 -0.188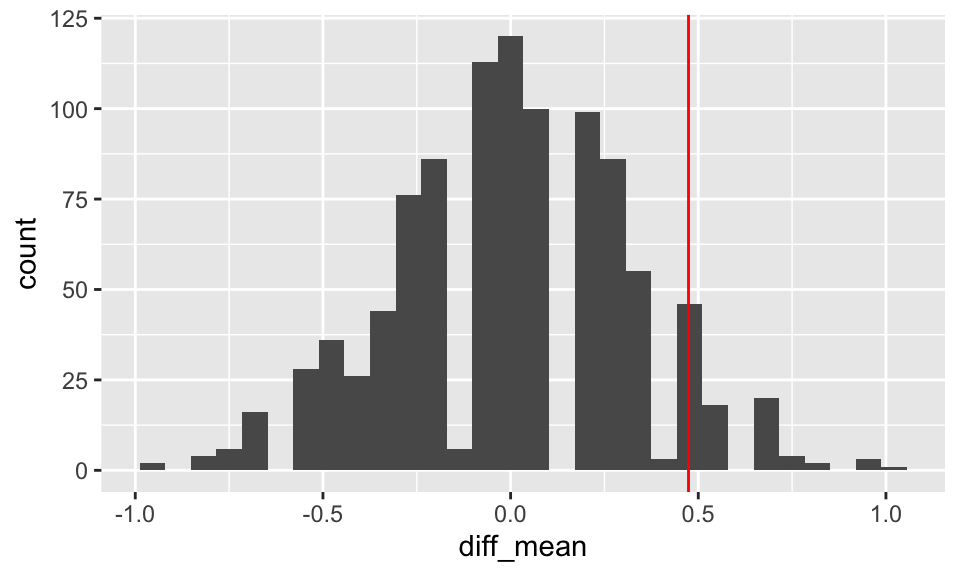 ]
]
5.3.3 Income and Health (F-like test)
Consider the NHANES dataset.
- Income
- (HHIncomeMid - Numerical version of HHIncome derived from the middle income in each category)
- Health
- (HealthGen - Self-reported rating of participant’s health in general Reported for participants aged 12 years or older. One of Excellent, Vgood, Good, Fair, or Poor.)
5.3.3.1 Summary of the variables of interest
## HealthGen
## Excellent Vgood Good Fair Poor
## 878 2508 2956 1010 187## HHIncomeMid
## Min. : 2500
## 1st Qu.: 30000
## Median : 50000
## Mean : 57206
## 3rd Qu.: 87500
## Max. :100000
## NA's :8115.3.3.2 Mean Income broken down by Health
NH.means <- NHANES %>%
filter(!is.na(HealthGen) & !is.na(HHIncomeMid)) %>%
group_by(HealthGen) %>%
summarize(IncMean = mean(HHIncomeMid, na.rm=TRUE), count=n())
NH.means## # A tibble: 5 × 3
## HealthGen IncMean count
## <fct> <dbl> <int>
## 1 Excellent 69354. 817
## 2 Vgood 65011. 2342
## 3 Good 55662. 2744
## 4 Fair 44194. 899
## 5 Poor 37027. 164Are the differences in means simply due to random chance??
NHANES %>% filter(!is.na(HealthGen)& !is.na(HHIncomeMid)) %>%
ggplot(aes(x=HealthGen, y=HHIncomeMid)) +
geom_boxplot() +
geom_jitter(width=0.1, alpha=.2)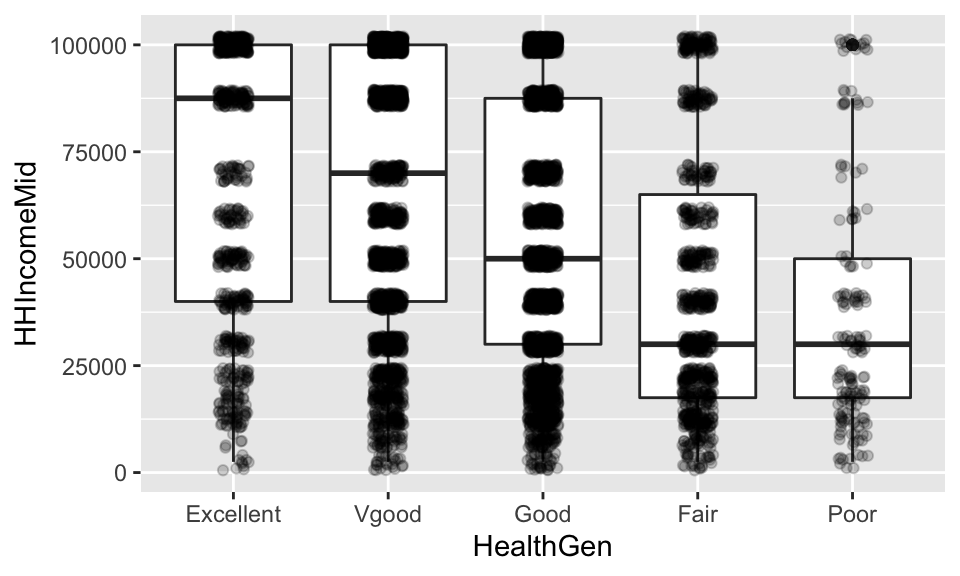
The differences in health, can be calculated directly, but we still don’t know if the differences are due to randome chance or some other larger structure.
## Excellent Vgood Good Fair Poor
## Excellent 0 4344 13692 25161 32327
## Vgood -4344 0 9348 20817 27983
## Good -13692 -9348 0 11469 18635
## Fair -25161 -20817 -11469 0 7166
## Poor -32327 -27983 -18635 -7166 05.3.3.3 Overall difference
We can measure the overall differences as the amount of variability between each of the means and the overall mean:
\[F = \frac{\text{between-group variability}}{\text{within-group variability}}\] \[F = \frac{\sum_i n_i(\overline{X}_{i\cdot} - \overline{X})^2/(K-1)}{\sum_{ij} (X_{ij}-\overline{X}_{i\cdot})^2/(N-K)}\] \[SumSqBtwn = \sum_i n_i(\overline{X}_{i\cdot} - \overline{X})^2\]
5.3.3.4 Creating a test statistic
## # A tibble: 6,966 × 2
## HHIncomeMid HealthGen
## <int> <fct>
## 1 30000 Good
## 2 30000 Good
## 3 30000 Good
## 4 40000 Good
## 5 87500 Vgood
## 6 87500 Vgood
## 7 87500 Vgood
## 8 30000 Vgood
## 9 100000 Vgood
## 10 70000 Fair
## # … with 6,956 more rows
## # ℹ Use `print(n = ...)` to see more rows
GM <- mean(NHANES$HHIncomeMid, na.rm=TRUE)
GM## [1] 57206
NH.means## # A tibble: 5 × 3
## HealthGen IncMean count
## <fct> <dbl> <int>
## 1 Excellent 69354. 817
## 2 Vgood 65011. 2342
## 3 Good 55662. 2744
## 4 Fair 44194. 899
## 5 Poor 37027. 164
NH.means$IncMean - GM## [1] 12148 7805 -1544 -13013 -20179
(NH.means$IncMean - GM)^2## [1] 1.48e+08 6.09e+07 2.38e+06 1.69e+08 4.07e+08
NH.means$count## [1] 817 2342 2744 899 164
NH.means$count * (NH.means$IncMean - GM)^2## [1] 1.21e+11 1.43e+11 6.54e+09 1.52e+11 6.68e+10\[SumSqBtwn = \sum_i n_i(\overline{X}_{i\cdot} - \overline{X})^2\]
## [1] 4.89e+115.3.3.5 Permuting the data
NHANES %>%
filter(!is.na(HealthGen)& !is.na(HHIncomeMid)) %>%
mutate(IncomePerm = sample(HHIncomeMid, replace=FALSE)) %>%
select(HealthGen, HHIncomeMid, IncomePerm) ## # A tibble: 6,966 × 3
## HealthGen HHIncomeMid IncomePerm
## <fct> <int> <int>
## 1 Good 30000 87500
## 2 Good 30000 70000
## 3 Good 30000 100000
## 4 Good 40000 40000
## 5 Vgood 87500 87500
## 6 Vgood 87500 100000
## 7 Vgood 87500 50000
## 8 Vgood 30000 50000
## 9 Vgood 100000 70000
## 10 Fair 70000 22500
## # … with 6,956 more rows
## # ℹ Use `print(n = ...)` to see more rows5.3.3.6 Permuting the data & a new test statistic
NHANES %>%
filter(!is.na(HealthGen)& !is.na(HHIncomeMid)) %>%
mutate(IncomePerm = sample(HHIncomeMid, replace=FALSE)) %>%
group_by(HealthGen) %>%
summarize(IncMeanP = mean(IncomePerm), count=n()) %>%
summarize(teststat = sum(count*(IncMeanP - GM)^2))## # A tibble: 1 × 1
## teststat
## <dbl>
## 1 14268151317.5.3.3.7 Lots of times…
reps <- 1000
SSB_perm_func <- function(.x){
NHANES %>%
filter(!is.na(HealthGen)& !is.na(HHIncomeMid)) %>%
mutate(IncomePerm = sample(HHIncomeMid, replace=FALSE)) %>%
group_by(HealthGen) %>%
summarize(IncMeanP = mean(IncomePerm), count=n()) %>%
summarize(teststat = sum(count*(IncMeanP - GM)^2))
}
SSB_perm_val <- map_dfr(1:reps, SSB_perm_func)
SSB_perm_val## # A tibble: 1,000 × 1
## teststat
## <dbl>
## 1 11839838857.
## 2 14805138617.
## 3 12238328218.
## 4 14493898296.
## 5 19052560418.
## 6 14099580957.
## 7 19808304723.
## 8 14972708855.
## 9 15543404291.
## 10 18334398022.
## # … with 990 more rows
## # ℹ Use `print(n = ...)` to see more rows5.3.3.8 Compared to the real data
SSB_obs <- NHANES %>%
filter(!is.na(HealthGen) & !is.na(HHIncomeMid)) %>%
group_by(HealthGen) %>%
summarize(IncMean = mean(HHIncomeMid), count=n()) %>%
summarize(obs_teststat = sum(count*(IncMean - GM)^2))
SSB_obs ## # A tibble: 1 × 1
## obs_teststat
## <dbl>
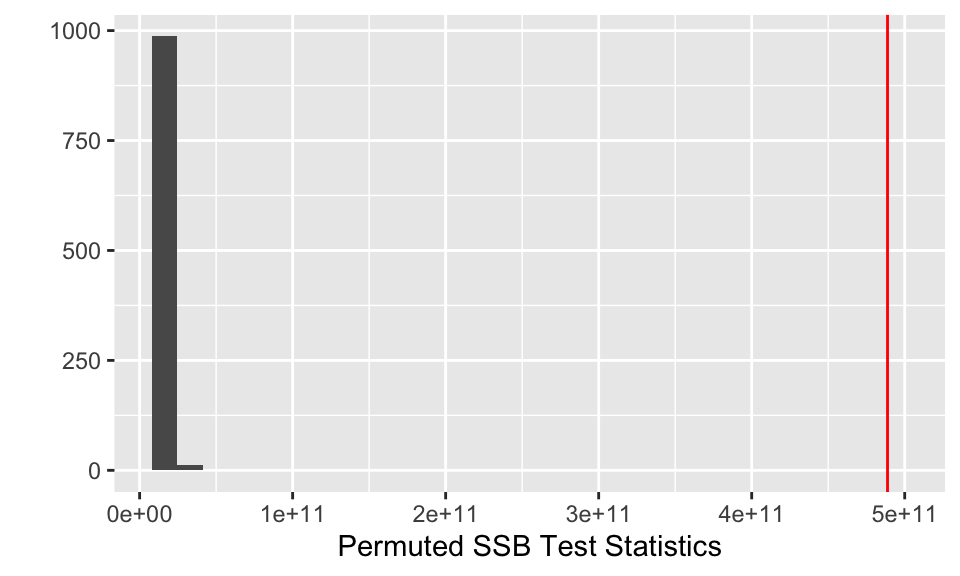
## 1 488767088754.## [1] 0
SSB_perm_val %>%
ggplot(aes(x = teststat)) +
geom_histogram() +
geom_vline(data = SSB_obs, aes(xintercept = obs_teststat), color = "red") +
ylab("") + xlab("Permuted SSB Test Statistics")