Randomization tests are best suited for modeling experiments where the treatment (explanatory variable) has been randomly assigned to the observational units and there is an attempt to answer a simple yes/no question.
For example, consider the following research questions that can be well assessed with a randomization test:
In this section, however, we are instead interested in estimating (not testing) the unknown value of a population parameter. For example,
For now, we explore the situation where focus is on a single proportion, and we introduce a new simulation method, bootstrapping.
Bootstrapping
Bootstrapping is best suited for modeling studies where the data have been generated through random sampling from a population. The goal of bootstrapping is to get an understanding of the variability of a statistic (from sample to sample). The variability of the statistic can be combined with the point estimate of the statistic in order to make claims about the population parameter.
In some cases (indeed, even in the case described here with one proportion!) a mathematical model can be used to describe the variability of a statistic of interest. We will encounter the mathematical models (including distributions such as the normal distribution, the t-distribution and the chi squared distribution) in later sections. However, for now, we will approximate the distribution of a statistic using repeated sampling.
The distribution of a statistic (called the Sampling Distribution) contains information (through, for example, a graph like a histogram or a mathematical model) on the possible values of the statistic and how often each of those values is likely to appear.
Recall (Example @ref(ex:helper) and Kissing example in HW) that with a hypothesized value of the true proportion (e.g., \(p=0.5\) with babies helping; \(p=0.8\) in kissing), we can understand / graph the possible values of \(\hat{p}\) under repeated samples. That is, if the true proportion of people who kiss to the right is \(p=0.8\), then if we select randomly from a bag with 80% red marbles (and 20% white marbles) we can understand the variability associated with the sample proportion of couples who kiss to the right in a sample of 124 couples.
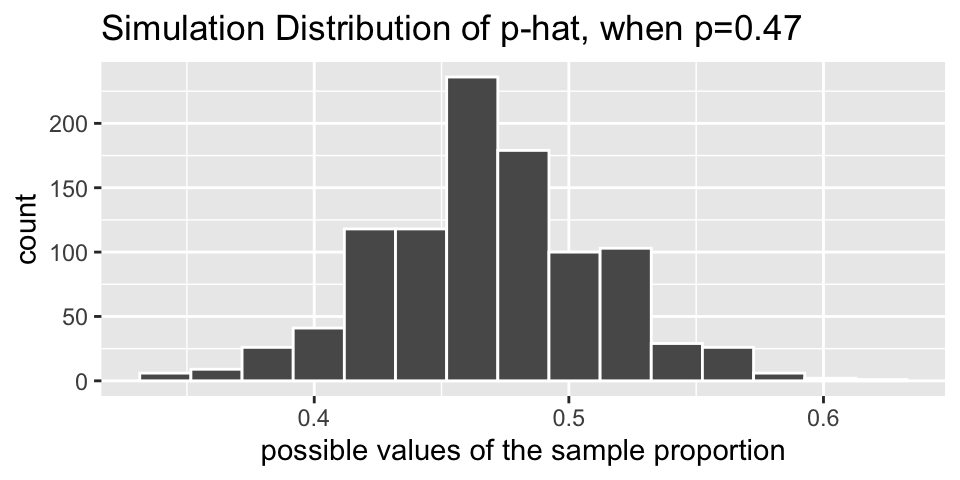
Let’s say you want to find out what proportion of videos on YouTube take place outside. You don’t have any idea what the true value is, but you’d like to estimate the population value. You take a random sample of 128 videos (there are lots of websites which will take random samples of YouTube videos, but tbh, I don’t know how “random” they actually are), and you find that 37 of them take place outside.
If you had originally hypothesized that 47% of YouTube videos happen outside, then the variability of the sample proportion can be described by the following histogram. That is to say, if each student in our class individually took a random sample of 128 YouTube videos (and again, with the condition that p = 0.47), their sample proportions would vary as below. To do the simulation with the computer, think about repeatedly selecting 128 marbles from a bag with 47% red.
But remember we are trying to model the situation where there is not a hypothesized value of the parameter in mind. That is, we need to use only the information in the sample to estimate the unknown characteristics about the population.
Due to theory that is beyond the scope of this book, it turns out that the if resamples are taken from the sample, they will vary around \(\hat{p}\) in the same way that individual samples will vary around \(p\). Let’s break that down a little bit.
As we saw in the figure above, when \(p=0.47\), the sample proportions vary from about 0.37 to 0.57, and they are centered at 0.47. That is, the sample proportions (\(\hat{p}\) values) vary around \(p=0.47\) by about plus or minus 0.1. Also, note that the shape of the distribution is reasonably bell-shaped and symmetric.
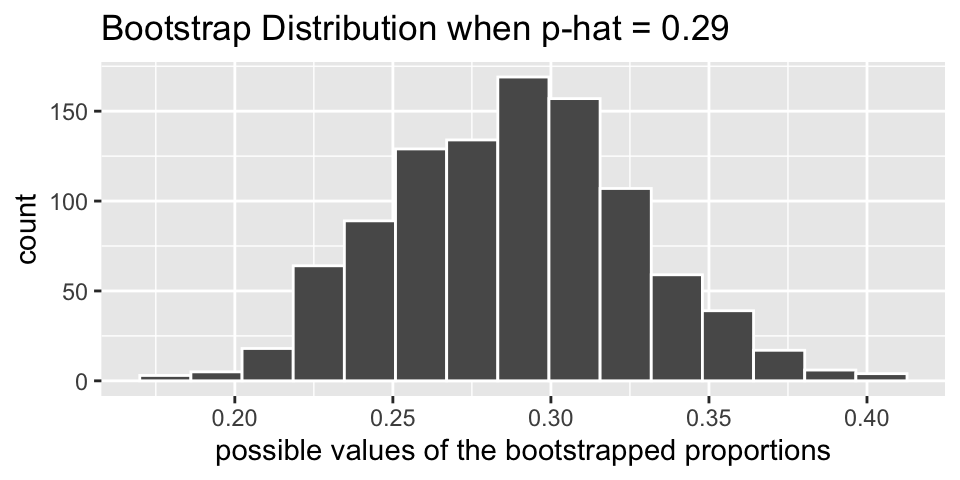
What happens if we use the data as a pseudo-population? In the actual dataset, 37 of the 128 videos took place outside. So \(\hat{p} = 0.29\). If the bag of marbles now has 29% red marbles (and 71% white marbles), how would the new bootstrapped sample proportions (\(\hat{p}_{boot}\)) vary? Note that with 29% red marbles in the bag, each resample has a bootstrapped proportion which now varies around 0.29! The range of possible values is still roughly plus or minus 0.1, and the shape of the distribution is bell-shaped and symmetric.
Resample. To resample is to select observations from the observed sample one at a time, measure them, replace them back into the population, and repeat until the new “resample” is exactly the same size as the original sample.
Note the physical object which connects to resampling is a bag of marbles. For example, in the kissing setting, the bag of marbles has 37 red marbles and 91 white marbles. By replacing the marble after it has been selected and its color recorded, we are effectively creating an infinitely large bag of marbles with 29% red.
The bootstrap process is typically referred to as resampling with replacement.
Two good applets for understanding bootstrapping and sampling distributions are:
- StatKey (Statistics: Unlocking the Power of Data) http://www.lock5stat.com/StatKey/bootstrap_1_cat/bootstrap_1_cat.html
- ISCAM http://www.rossmanchance.com/applets/2021/oneprop/OneProp.htm
Bootstrapping Confidence Intervals
A point estimate (also called a statistic) gives a single value for the best guess of the parameter of interest. Although it is the best guess, it is rarely perfect, and we expect that there is some error (i.e., variability) in the estimated value. A confidence interval provides a range of plausible values for the parameter. A confidence level is the long-run percent of intervals that capture the true parameter.
Reminder of where we are:
- The goal is to find an interval of plausible values for a parameter, the true proportion \(p\).
- We are working with only one dataset, that is, one sample proportion \(\hat{p}\).
- We can resample from the original dataset (where resample is called bootstrapping) to find out the shape of how sample proportions vary.
- Due to theory that is beyond the scope of this book, it turns out that the if resamples are taken from the sample, they will vary around \(\hat{p}\) in the same way that individual samples will vary around \(p\).
If you are two feet from me, then I am two feet from you.
95% Bootstrap Percentile Confidence Interval for \(p\)
From the bootstrapped proportions, find the bootstrap value at 2.5% and 97.5% and refer to them as “lower” and “upper” respectively.
The interval given by: (lower, upper) will be a 95% confidence interval for \(p\).
Note that the “95%” value is the confidence level and describes how often the process outlined above will actually work to capture the true parameter of interest.
As you might suspect, if the goal is to create intervals that capture the true parameter at a lower rate (say, 90%) then the endpoints of the interval will be taken from the 5% and 95% bootstrapped proportion values. If the goal is to create intervals that capture the true parameter at a higher rate (say, 99%) then the endpoints of the interval will be taken from the 0.5% and 99.5% bootstrapped proportion values. The larger confidence level will capture the true parameter at a higher rate (which is a good thing!), but it comes at a cost of also creating an interval that is much wider than a 90% interval. An interval that is too wide will not be helpful in trying to understand the population at hand (which is why we don’t attempt to create “100% intervals” which would be given by (0,1), useless for learning anything new).
A note on sample size
By working with the applets, you may notice that the variability of the proportions decreases substantially with larger sample sizes. However the rate by which an confidence procedure captures the parameter is completely separated from the value of the sample sizes. The confidence procedure will capture at the set rate regardless of sample size. A larger sample size will create more narrow intervals (than a small sample size), but it will not capture the true parameter any more often.